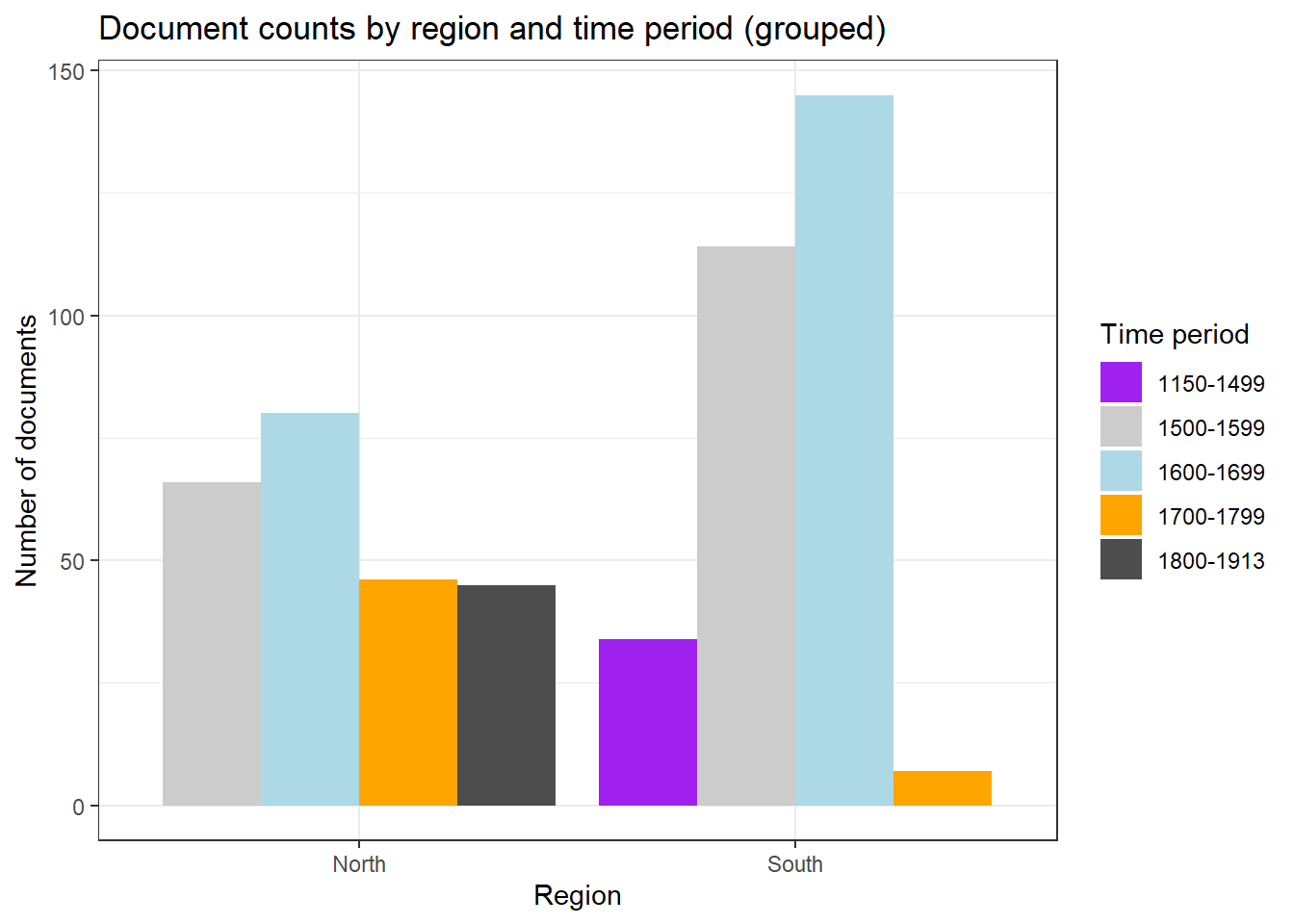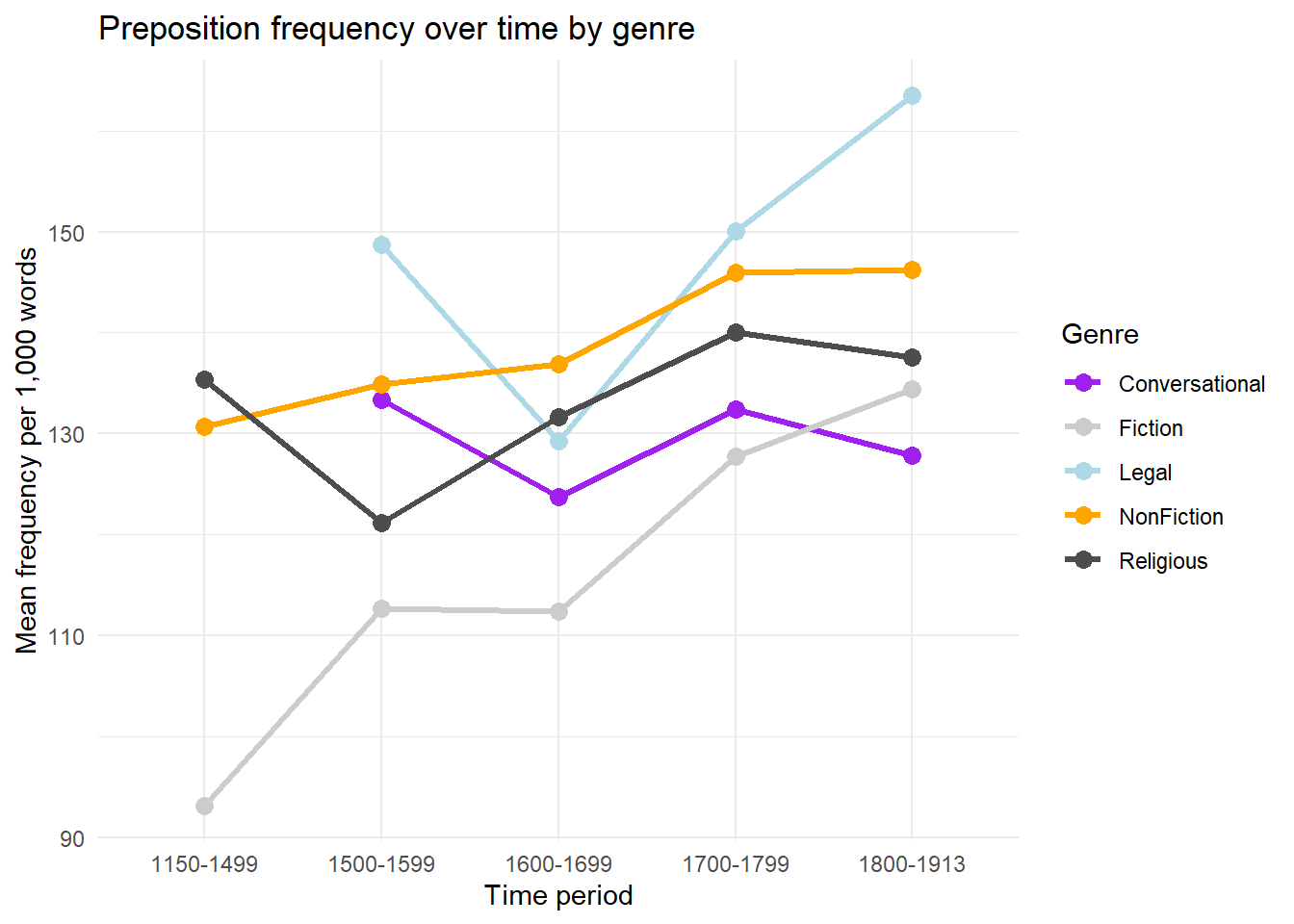This tutorial covers advanced data visualisation techniques in R using ggplot2, including faceting, small multiples, complex data transformations for visualisation, combining multiple plots, and creating interactive visualisations. It is aimed at researchers in linguistics and the humanities who have a basic familiarity with ggplot2 and want to expand their visualisation toolkit.
Author
Martin Schweinberger
Published
2026
Great Court, The University of Queensland
Introduction
This tutorial introduces data visualisation with R, focusing on the ggplot2 package. It covers a wide range of plot types suited to different data structures and research questions — from scatter plots and distribution plots to Likert scale visualisations, heatmaps, time series, and publication-ready figures. Throughout, the emphasis is on choosing the right visualisation for a given question, understanding the grammar of graphics that underlies ggplot2, and developing the habits that lead to clear, reproducible, and honest data communication.
The tutorial works through a concrete dataset on preposition frequencies in historical English texts, providing a continuous research narrative that connects the individual examples. Exercises at the end of each section consolidate understanding.
Learning Objectives
By the end of this tutorial you will be able to:
Explain the grammar of graphics and how it structures ggplot2 code
Choose an appropriate visualisation type for a given data structure and research question
Create scatter plots, density plots, histograms, ridge plots, boxplots, violin plots, bar plots, heatmaps, line graphs, and ribbon plots in ggplot2
Visualise Likert scale survey data using grouped bar plots and gglikert
Customise plots with themes, colour palettes, labels, and annotations
Apply accessibility principles including redundant encoding and colourblind-safe palettes
Combine multiple plots into a single figure using patchwork
Save publication-quality figures in appropriate formats and resolutions
Avoid common visualisation mistakes including truncated axes, chartjunk, and overplotting
Prerequisite Tutorials
Before working through this tutorial, you should be familiar with:
Martin Schweinberger. 2026. Mastering Data Visualization with R. The Language Technology and Data Analysis Laboratory (LADAL), The University of Queensland, Australia. url: https://ladal.edu.au/tutorials/data_viz_advanced/data_viz_advanced.html (Version 3.1.1). doi: 10.5281/zenodo.19332872.
Setup and Preparation
Section Overview
What you will learn: Which packages are needed and why; how to load the tutorial dataset; and how to set up a consistent colour palette for use throughout the tutorial
Installing required packages
Run this code once to install all required packages. It may take a few minutes.
Code
install.packages("dplyr")install.packages("stringr")install.packages("ggplot2")install.packages("tidyr")install.packages("scales")install.packages("ggridges")install.packages("ggstats")install.packages("ggstatsplot")install.packages("EnvStats")install.packages("likert")install.packages("vcd")install.packages("hexbin")install.packages("patchwork") # Combining multiple plotsinstall.packages("viridis") # Colourblind-safe palettesinstall.packages("flextable")install.packages("devtools")# Install ggflags from GitHub (country flags in plots)devtools::install_github("jimjam-slam/ggflags")
We work throughout this tutorial with a dataset on preposition frequencies in historical English texts from the Penn Parsed Corpora of Historical English (PPCME, PPCEME, PPCMBE). Each row represents one text, and the key variables are described below.
DateRedux — time period categories (1150–1499, 1500–1599, etc.)
Setting up a colour palette
Using a consistent colour palette across all visualisations creates a coherent, professional look and reduces the cognitive load of switching between colour schemes. We define five colours here that we will reuse throughout.
For accessibility, prefer palettes from the viridis package or scale_color_brewer() with "Set2" or "Dark2".
Part 1: The Grammar of Graphics
Section Overview
What you will learn: The conceptual framework underlying ggplot2; the seven components of every plot; and how to read and write ggplot2 code systematically
Why ggplot2?
ggplot2 is the dominant data visualisation package in R for good reason. It is based on a coherent theoretical framework — the grammar of graphics — that makes it possible to construct any plot from a small set of building blocks. Rather than memorising individual plot functions, you learn a system: once you understand the grammar, you can build plots you have never seen before by composing components in new ways.
The grammar of graphics, formalised by Wilkinson (2005) and implemented in ggplot2 by Wickham (2010), describes a plot as the result of mapping data to aesthetics through geometric objects, with additional components controlling scales, coordinate systems, facets, and themes.
The seven components
Every ggplot2 plot is built from up to seven components:
1. Data — the data frame containing the variables to be visualised. Passed as the first argument to ggplot().
2. Aesthetics (aes()) — the mapping from data variables to visual properties: which variable goes on the x-axis, which on the y-axis, which controls colour, size, shape, transparency, and so on. Aesthetics defined inside ggplot() apply to all layers; aesthetics inside a specific geom_*() apply only to that layer.
3. Geometries (geom_*()) — the geometric objects used to represent the data. Points, lines, bars, boxes, ribbons, tiles, and text are all geometries. Each geom_*() call adds a new layer to the plot.
4. Scales (scale_*()) — control how aesthetic mappings are translated into visual properties. For example, scale_color_manual() specifies exact colours; scale_x_log10() log-transforms the x-axis; scale_y_continuous(labels = scales::percent) formats y-axis labels as percentages.
5. Facets (facet_wrap(), facet_grid()) — split the data into subplots by the values of one or more categorical variables. Faceting is one of the most powerful features of ggplot2 for comparing patterns across groups.
6. Coordinate system (coord_*()) — controls the space in which the plot is drawn. coord_flip() swaps x and y; coord_polar() creates polar (circular) coordinates; coord_cartesian() sets axis limits without dropping data points.
7. Theme (theme_*(), theme()) — controls all non-data visual elements: background colour, gridlines, font sizes, axis tick marks, legend position, and so on. theme_bw() and theme_minimal() are good defaults for publication work.
The ggplot2 template
Every ggplot2 call follows this template:
Code
ggplot(data =<DATA>, aes(x =<X>, y =<Y>, color =<GROUP>)) + geom_<TYPE>(<PARAMETERS>) + scale_<AESTHETIC>_<TYPE>(<PARAMETERS>) + facet_<TYPE>(vars(<VARIABLE>)) + coord_<TYPE>() + theme_<STYLE>() +labs(title ="<TITLE>", x ="<X LABEL>", y ="<Y LABEL>")
The + operator adds layers and components to the plot. The order generally does not matter for the final result, but it is conventional to put data layers first, then scales, then facets, then theme, then labels.
Reading existing ggplot2 code
When you encounter unfamiliar ggplot2 code, read it layer by layer. Ask: what data is being used? What is mapped to x, y, colour, and other aesthetics? What geometric objects are being drawn? What scales and themes have been applied? This decomposition makes even complex plots understandable.
Part 2: Exploring Relationships
Section Overview
What you will learn: Scatter plots as the foundation for showing relationships between two continuous variables; adding colour, shape, and trend lines; using facets; managing overplotting with transparency, density contours, and hex plots
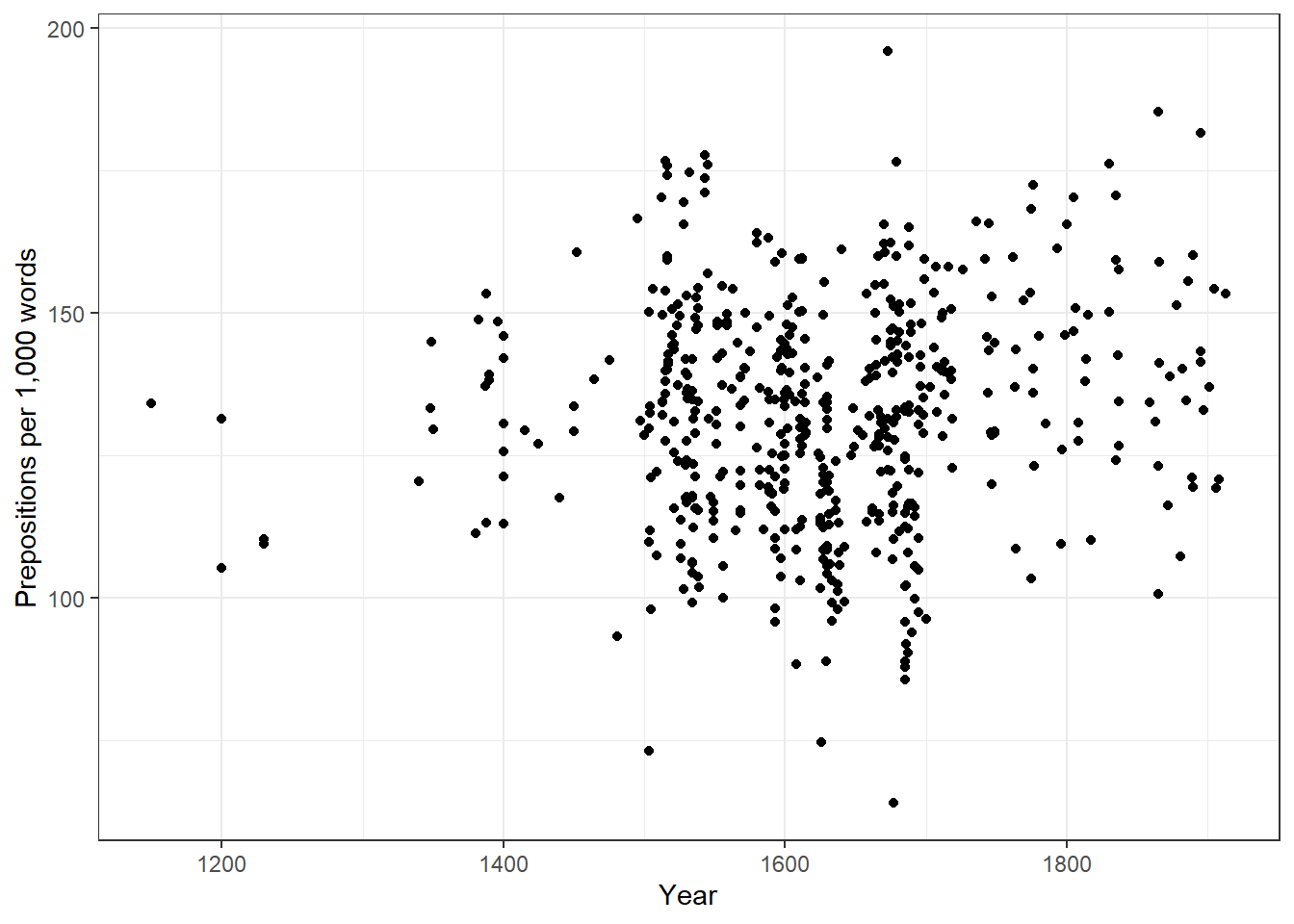
Scatter plots
Scatter plots are the most direct way to visualise the relationship between two continuous variables. Each point represents one observation.
When to use: Two continuous variables; sample size small enough that individual points can be seen (roughly < 5,000 without overplotting strategies).
ggplot() initialises the plot and sets the default data and aesthetics
aes(x = Date, y = Prepositions) maps the variable Date to the x-axis and Prepositions to the y-axis
geom_point() adds a layer of points — one per row in the data
theme_bw() applies a clean black-and-white theme
labs() sets axis labels
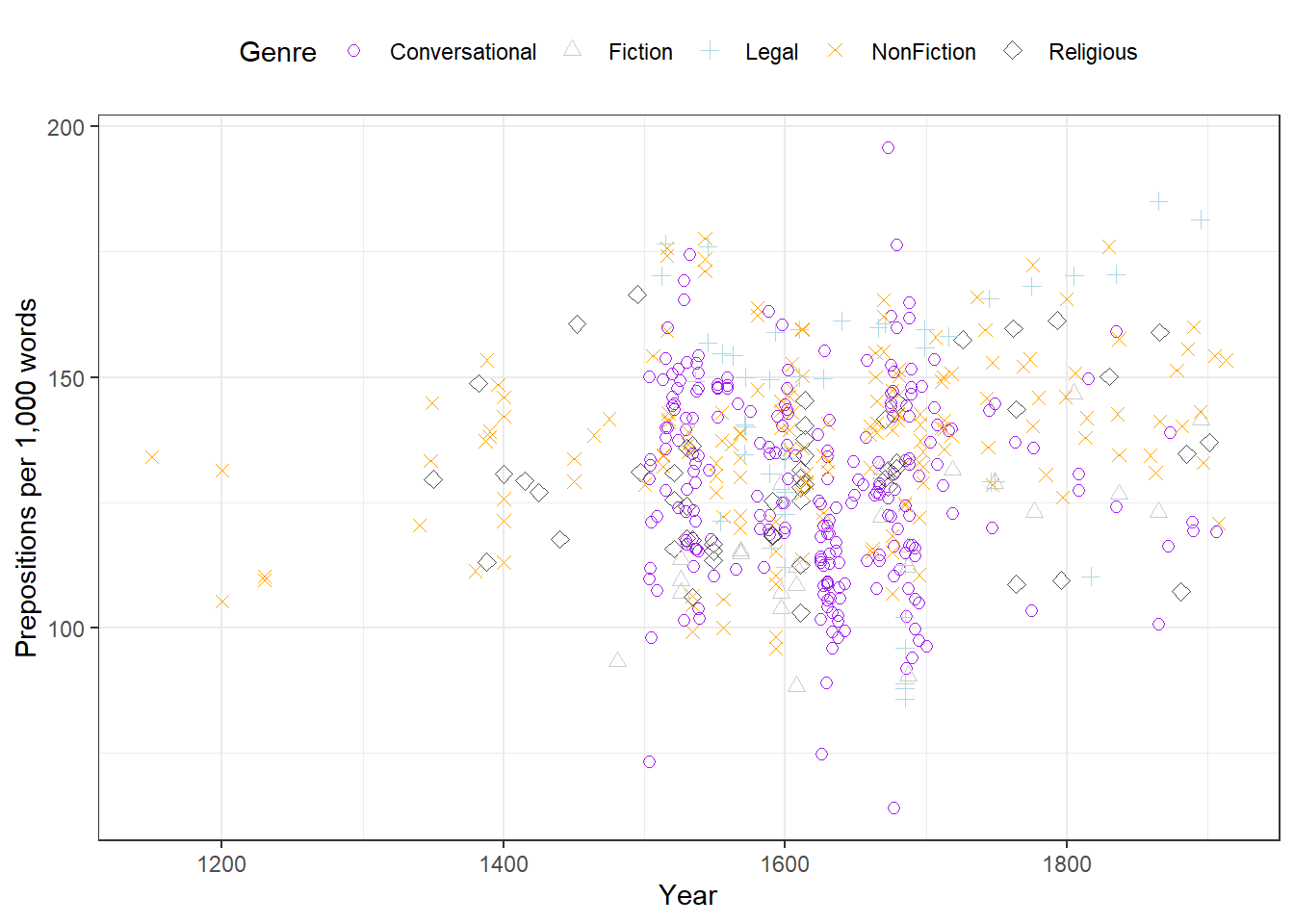
Adding colour and shape
Using both colour and shape to encode the same variable is called redundant encoding. It makes plots more accessible: readers who cannot distinguish colours (about 8% of men have some form of colour vision deficiency) can still use the shapes, and the plot retains its meaning when printed in greyscale.
When points from multiple groups overlap, faceting into separate panels makes individual group patterns visible. Adding a trend line with geom_smooth() makes the overall direction of change within each group explicit.
Code
ggplot(pdat, aes(Date, Prepositions, color = Genre)) +facet_wrap(vars(Genre), ncol =4) +geom_point(alpha =0.4) +geom_smooth(method ="lm", se =FALSE, linewidth =0.8) +theme_bw() +theme(legend.position ="none",axis.text.x =element_text(size =8, angle =90) ) +labs(x ="Year", y ="Prepositions per 1,000 words")
Facets: when to use them
Facets work best when you have 3–8 groups whose within-group patterns are the focus, and when direct across-group value comparison is less important than seeing each group’s trend clearly. Avoid facets when groups need to be directly overlaid for comparison, or when you have more than about 10 groups.
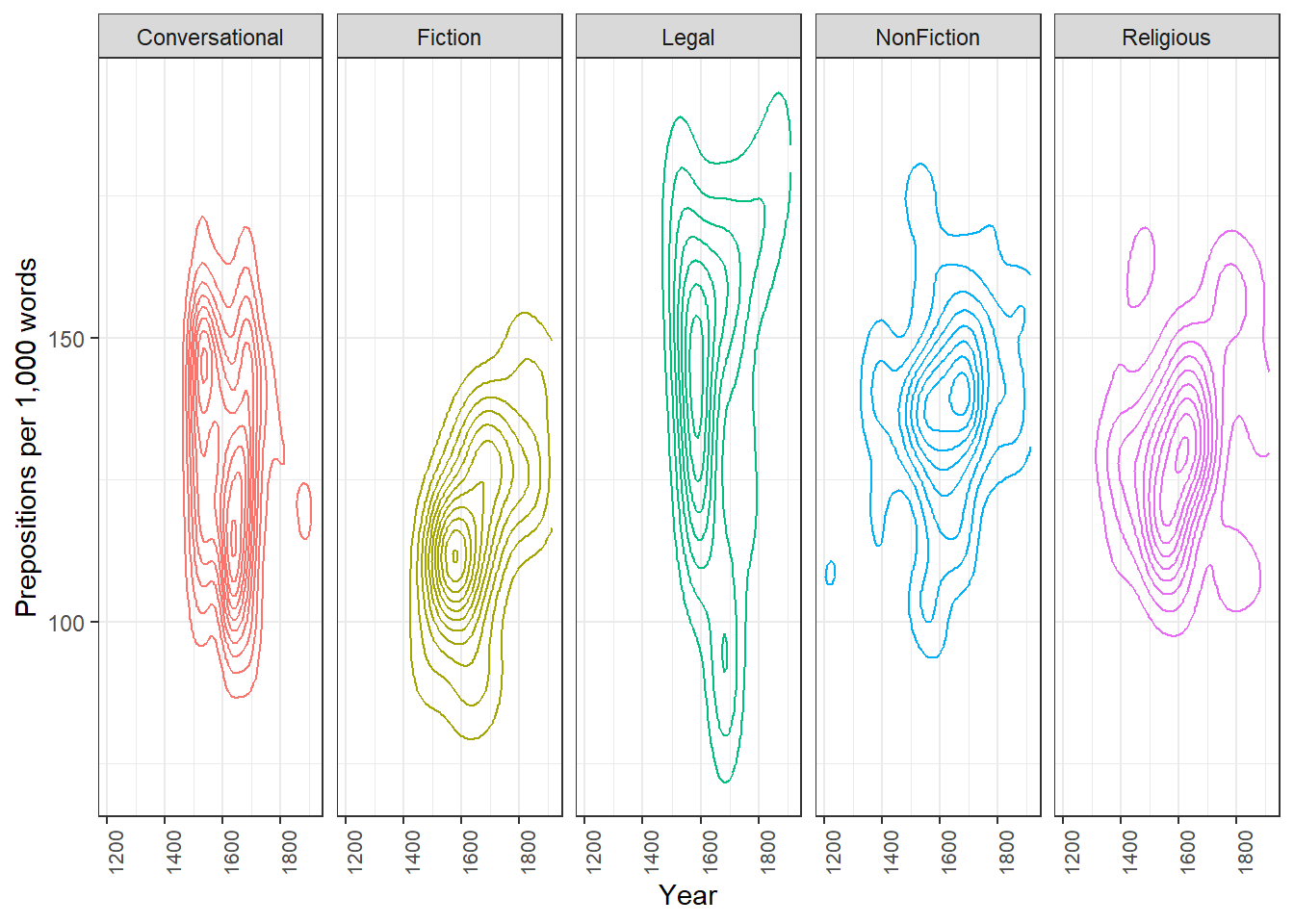
Managing overplotting
When many points occupy the same region, individual points become invisible. Three strategies address this:
Transparency (alpha) — making points semi-transparent so density is visible as colour intensity.
2D density contours (geom_density_2d) — contour lines showing where data is concentrated, like a topographic map.
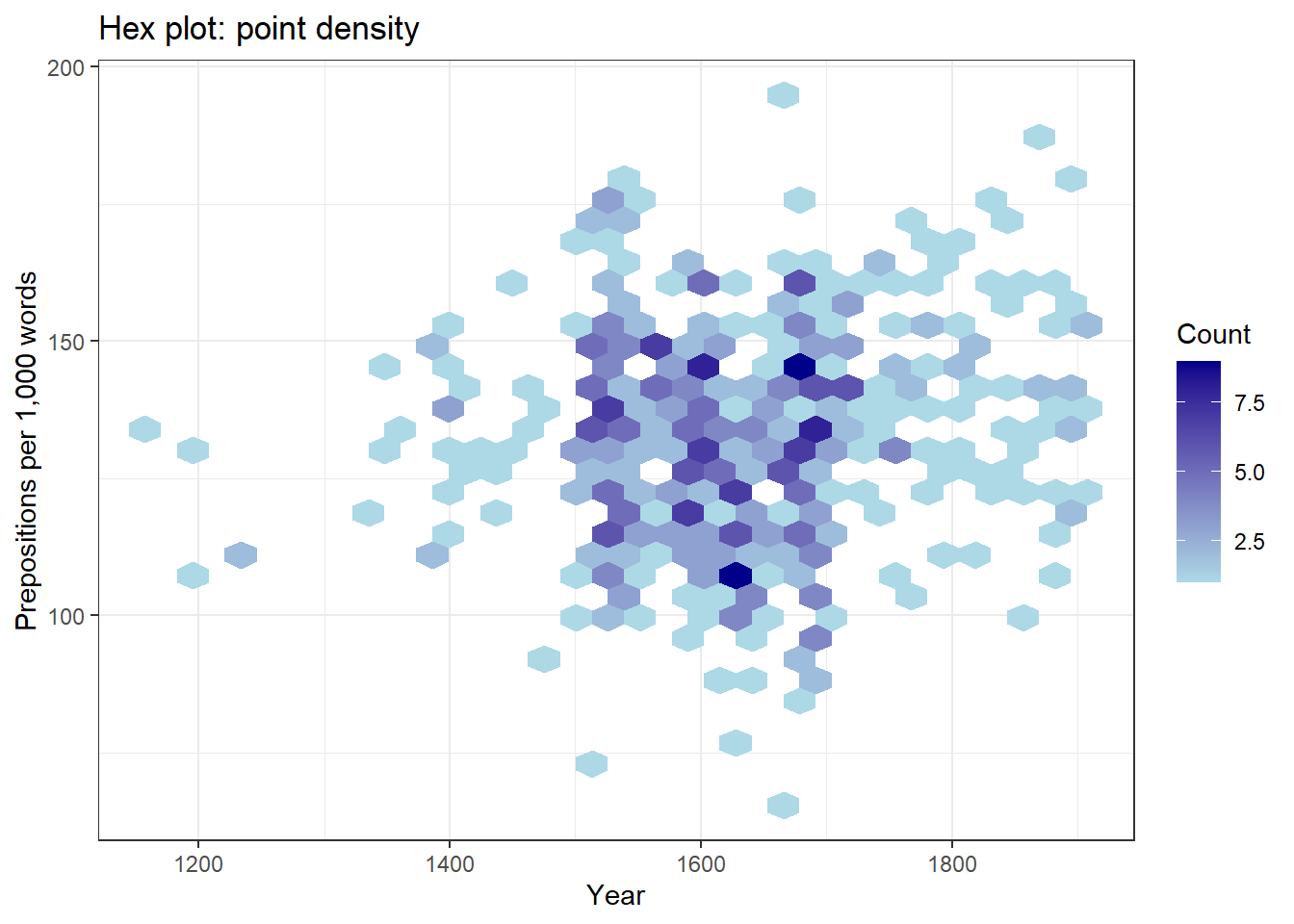
Hex plots (geom_hex) — the plotting region is divided into hexagonal bins; each bin is coloured by the number of points it contains. Effective for very large datasets.
Code
ggplot(pdat, aes(x = Date, y = Prepositions, color = GenreRedux)) +facet_wrap(vars(GenreRedux), ncol =5) +geom_density_2d() +theme_bw() +theme(legend.position ="none",axis.text.x =element_text(size =8, angle =90) ) +labs(x ="Year", y ="Prepositions per 1,000 words")
Code
pdat |>ggplot(aes(x = Date, y = Prepositions)) +geom_hex() +scale_fill_gradient(low ="lightblue", high ="darkblue",name ="Count") +theme_bw() +labs(x ="Year", y ="Prepositions per 1,000 words",title ="Hex plot: point density")
Approach
Best for
Limitation
Points
Small–medium datasets, seeing all data
Gets cluttered with many points
Transparency
Moderate overplotting
Still unclear at very high density
Density contours
Showing concentration patterns
Harder to interpret than points
Hex bins
Very large datasets
Requires comparable x–y scales
Part 3: Showing Distributions
Section Overview
What you will learn: Density plots, histograms, ridge plots, boxplots, and violin plots — when each is appropriate and what each reveals that the others do not
Density plots
Density plots show the estimated probability density of a continuous variable as a smooth curve. They are particularly useful for comparing the shape of a distribution across groups.
Code
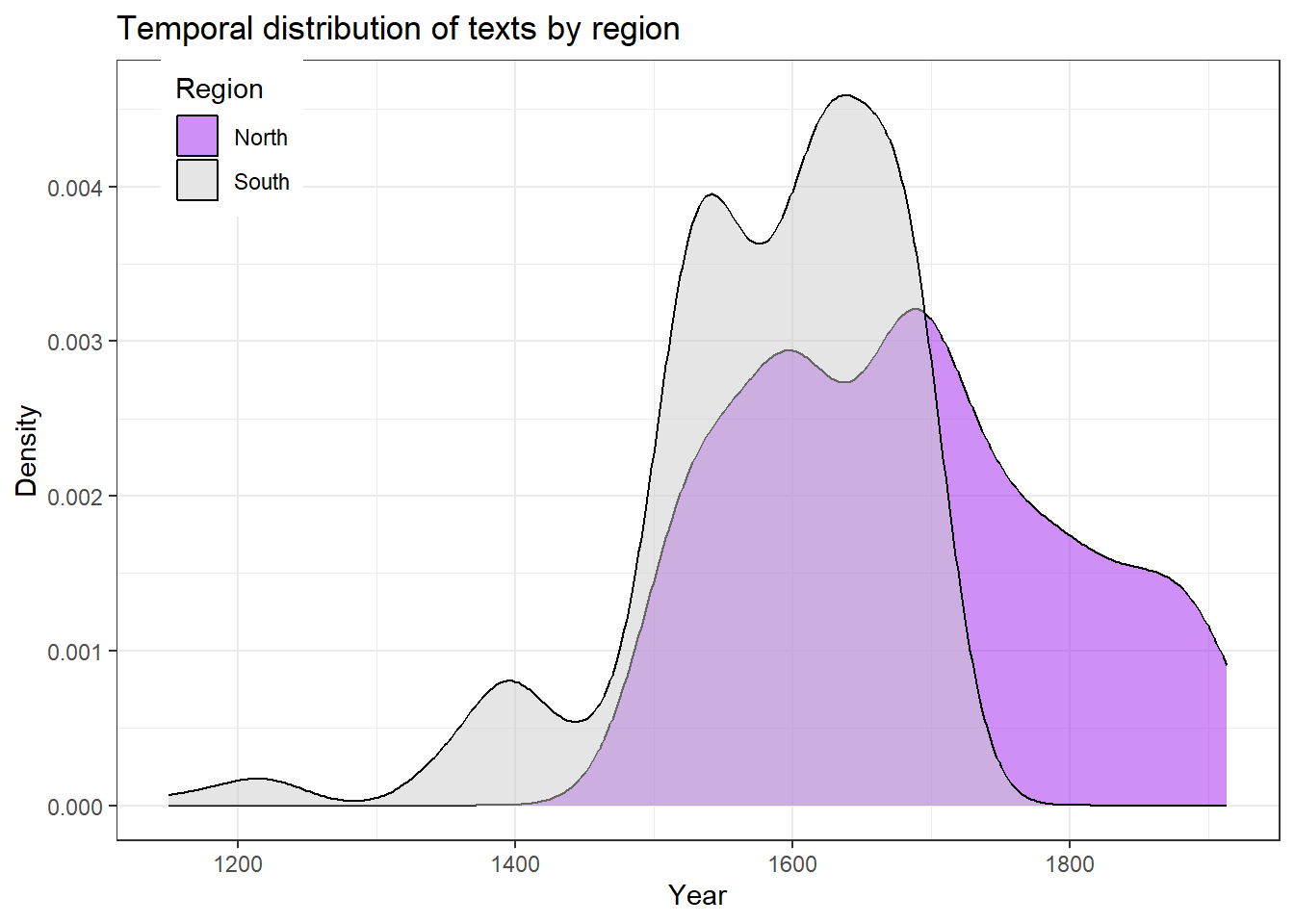
ggplot(pdat, aes(Date, fill = Region)) +geom_density(alpha =0.5) +scale_fill_manual(values = clrs[1:2]) +theme_bw() +theme(legend.position =c(0.1, 0.9)) +labs(x ="Year", y ="Density",title ="Temporal distribution of texts by region")
The plot shows that southern texts continue into the 1800s while northern texts end around 1700, with a period of overlap in between.
Histograms
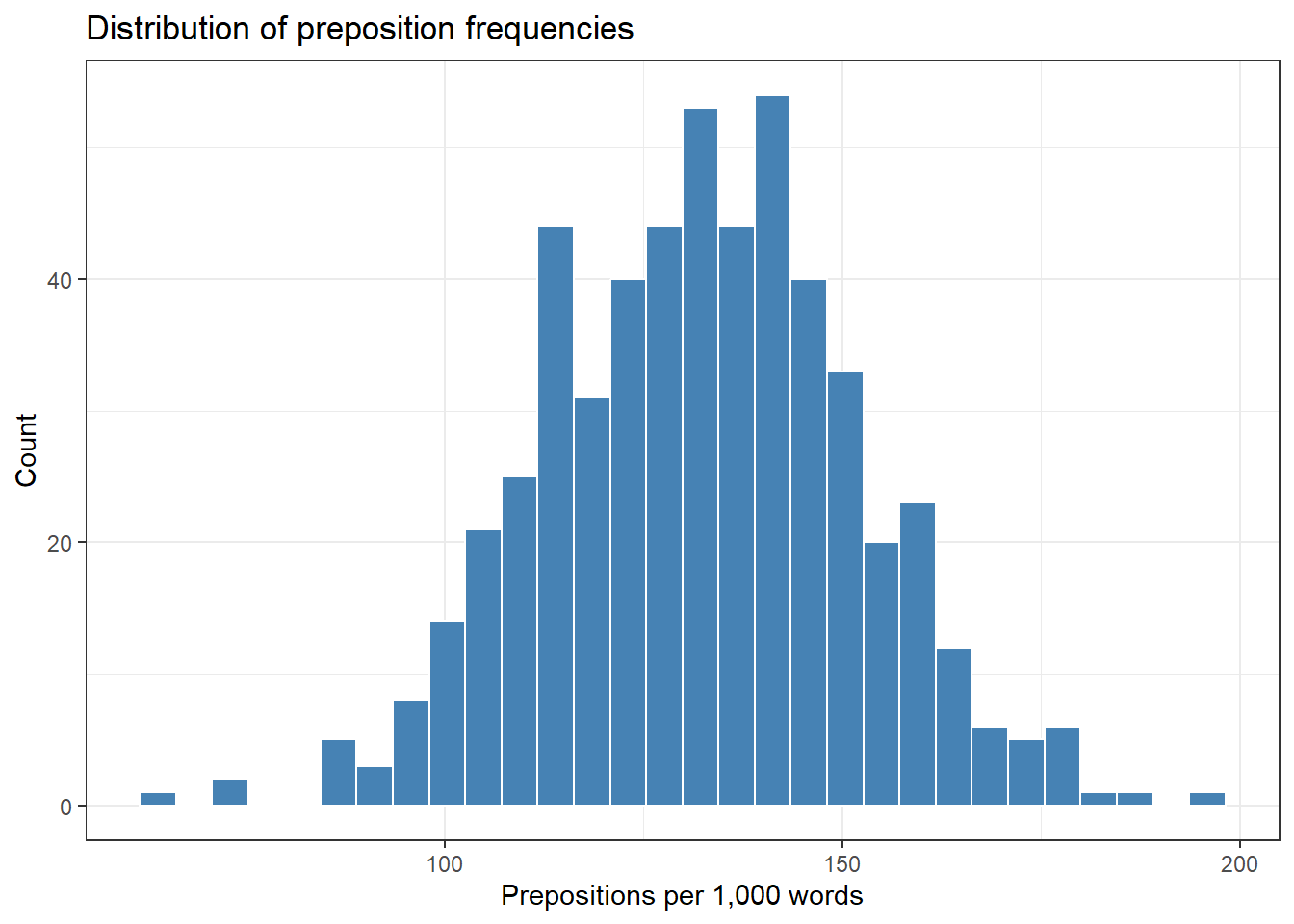
Histograms divide a continuous variable into equal-width bins and count how many observations fall in each. Unlike density plots, they show actual counts and make the discretisation of the data explicit.
Code
ggplot(pdat, aes(Prepositions)) +geom_histogram(bins =30, fill ="steelblue", color ="white") +theme_bw() +labs(title ="Distribution of preposition frequencies",x ="Prepositions per 1,000 words",y ="Count")
Histogram vs. bar plot
A histogram shows the distribution of one continuous variable. The bins are ranges of values, and there are no gaps between bars (the variable is continuous).
A bar plot shows counts or values for discrete categories. Bars are separated by gaps to reflect the categorical (not continuous) nature of the x-axis.
Confusing the two is one of the most common plotting mistakes in student work.
Ridge plots
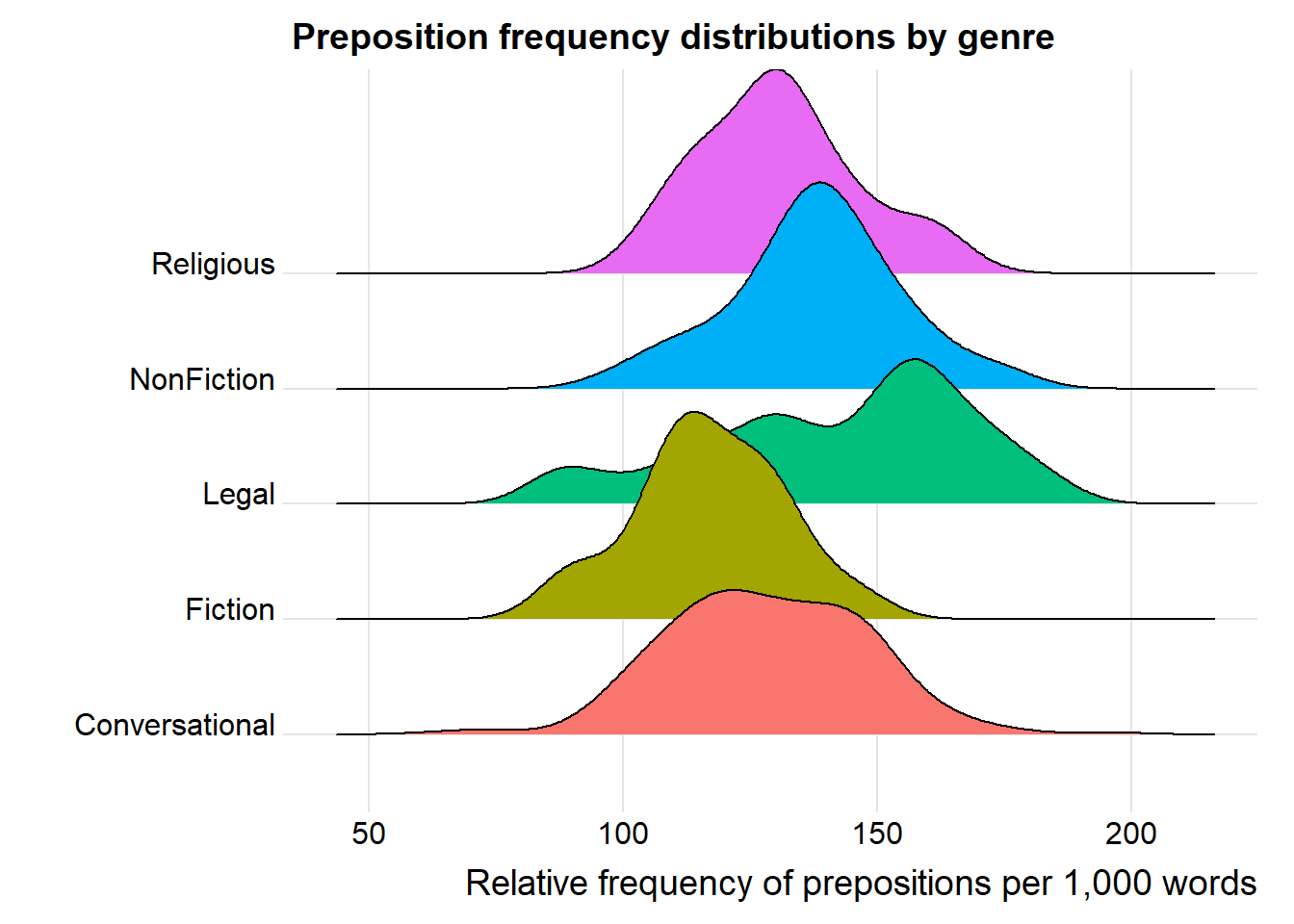
Ridge plots (also called joy plots) show offset density curves for multiple groups, making it easy to compare shapes across many groups simultaneously. They are particularly effective when you have more groups than can comfortably be shown in overlapping densities.
Code
pdat |>ggplot(aes(x = Prepositions, y = GenreRedux, fill = GenreRedux)) +geom_density_ridges() +theme_ridges() +theme(legend.position ="none") +labs(y ="", x ="Relative frequency of prepositions per 1,000 words",title ="Preposition frequency distributions by genre")
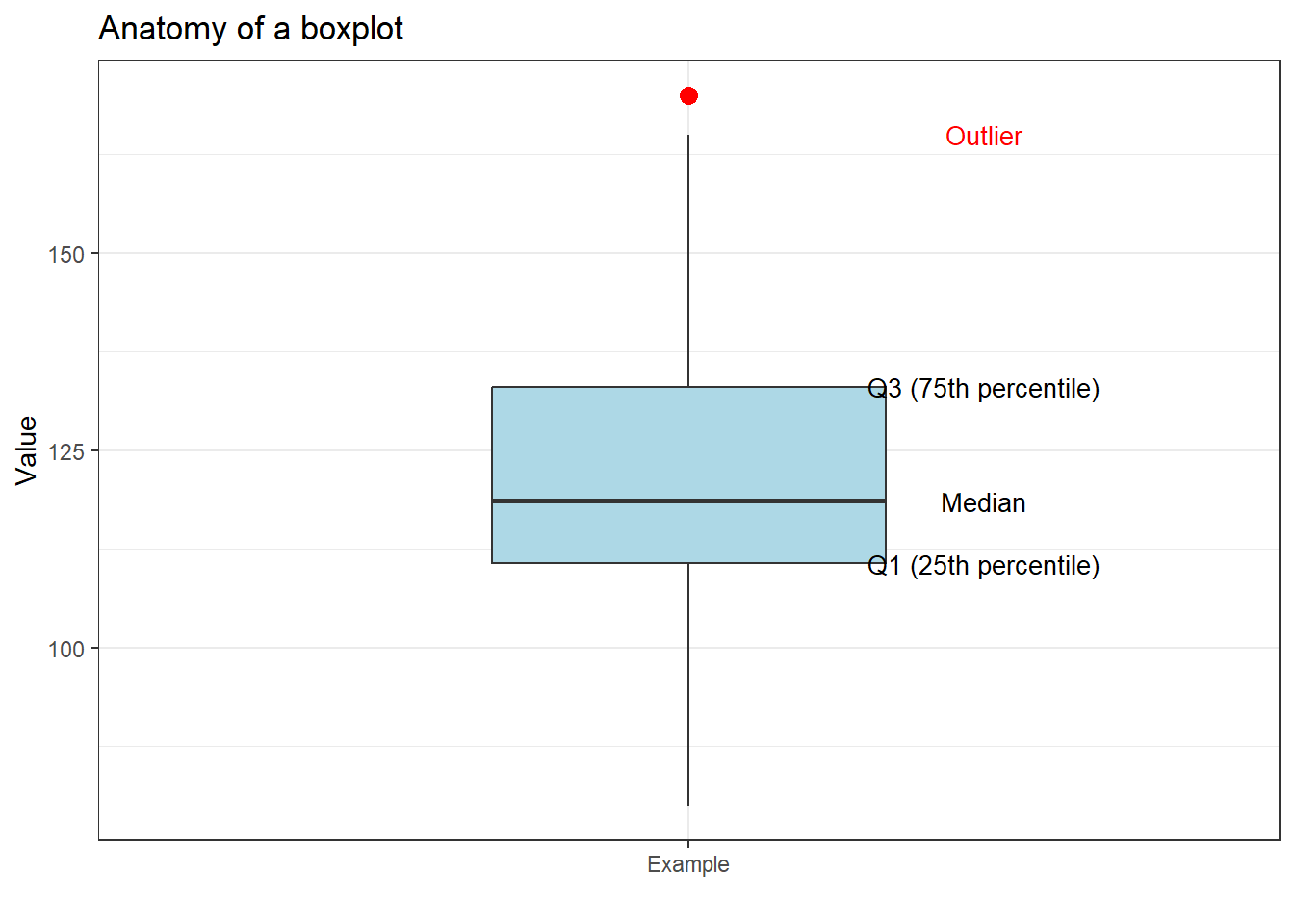
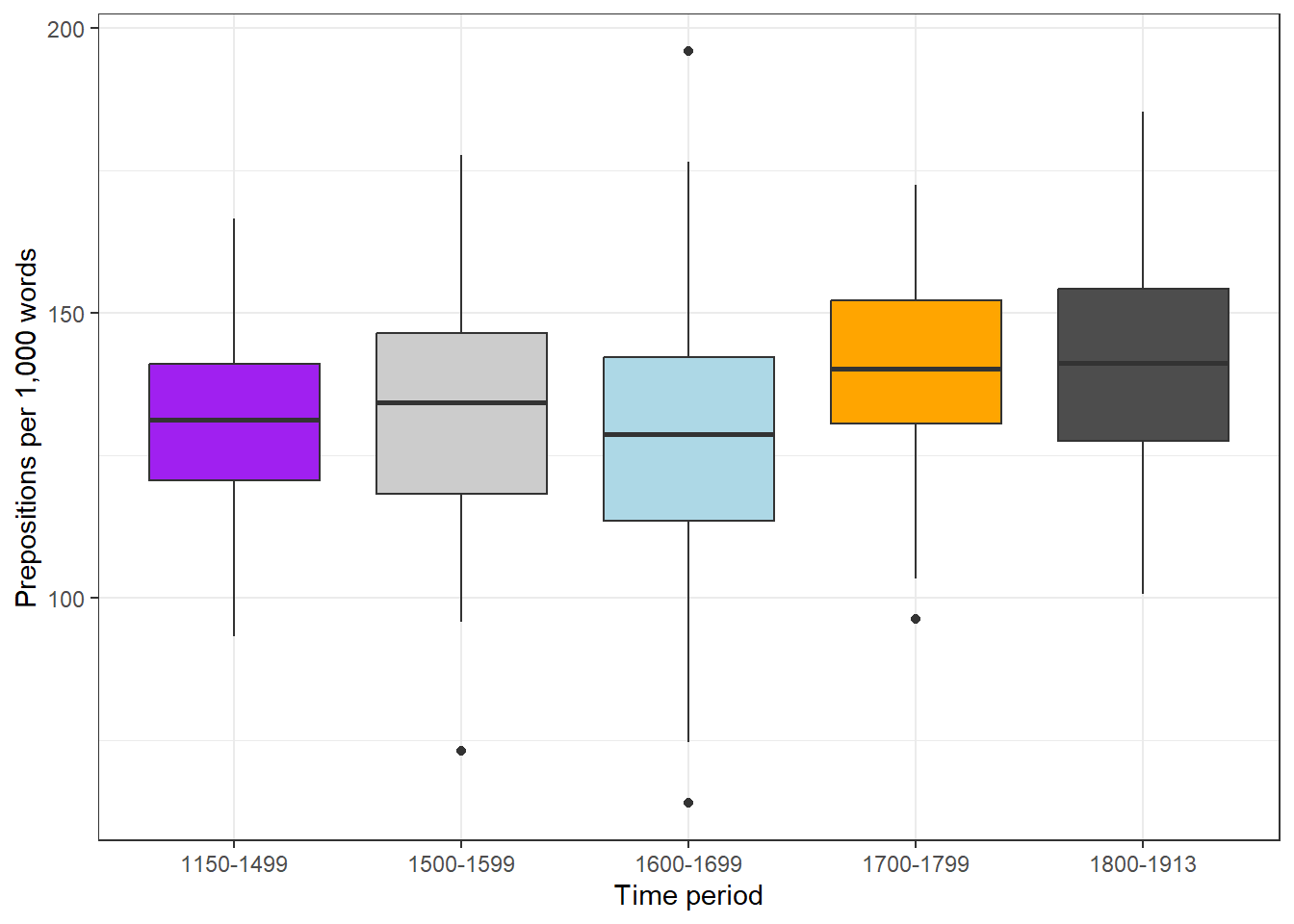
Boxplots
Boxplots display five summary statistics simultaneously: the median (line inside the box), the first and third quartiles (the box edges, enclosing the interquartile range, IQR), and the whiskers extending to 1.5 times the IQR beyond each box edge. Points beyond the whiskers are plotted individually as potential outliers.
Code
ggplot(pdat, aes(DateRedux, Prepositions, fill = DateRedux)) +geom_boxplot() +scale_fill_manual(values = clrs) +theme_bw() +theme(legend.position ="none") +labs(x ="Time period", y ="Prepositions per 1,000 words")
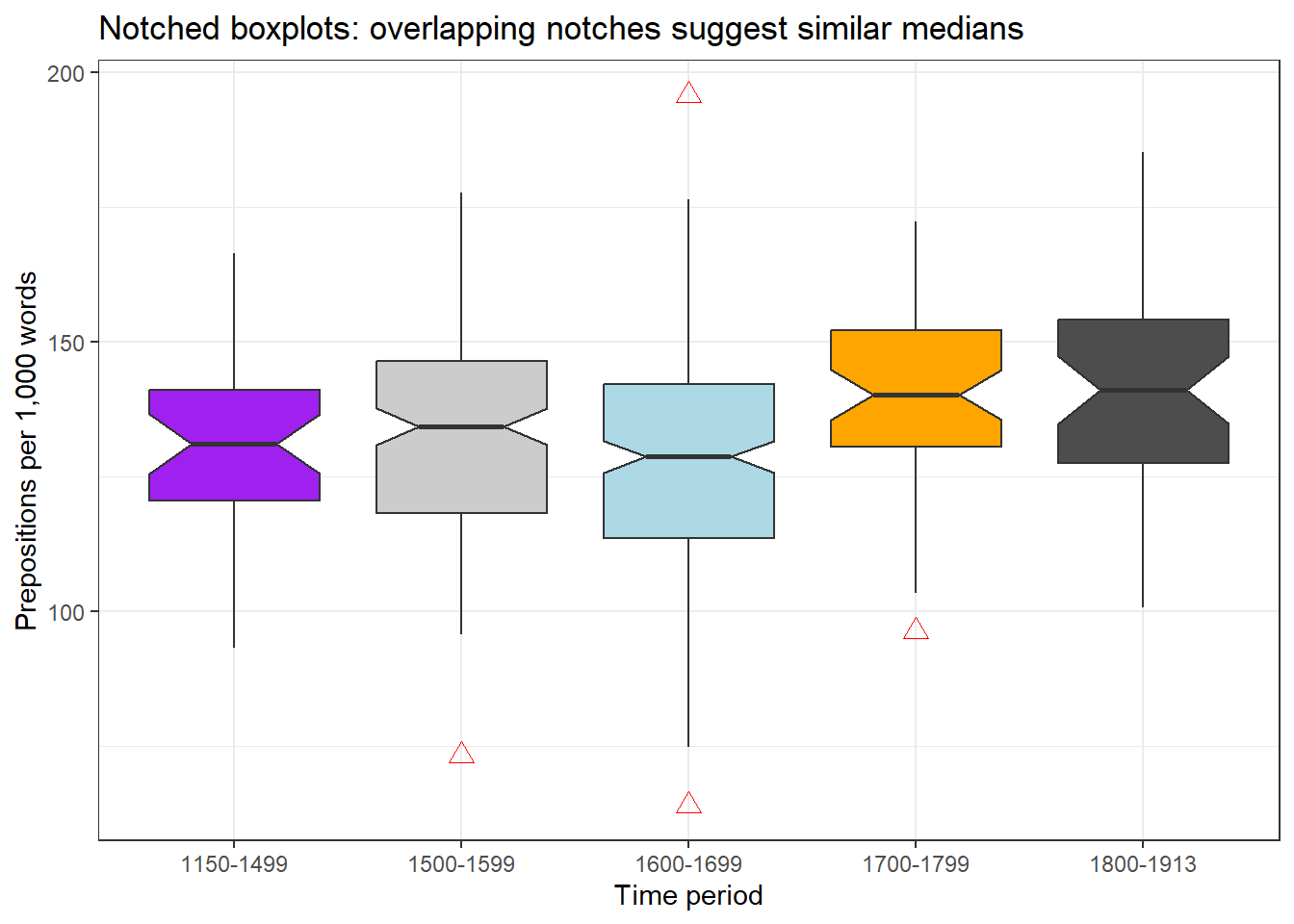
Notched boxplots
Adding notch = TRUE draws notches around the median. If notches of two boxes do not overlap, there is strong visual evidence that the medians differ significantly. This is a useful quick check, though it is not a substitute for formal statistical testing.
Code
ggplot(pdat, aes(DateRedux, Prepositions, fill = DateRedux)) +geom_boxplot(notch =TRUE,outlier.colour ="red",outlier.shape =2,outlier.size =3) +scale_fill_manual(values = clrs) +theme_bw() +theme(legend.position ="none") +labs(x ="Time period", y ="Prepositions per 1,000 words",title ="Notched boxplots: overlapping notches suggest similar medians")
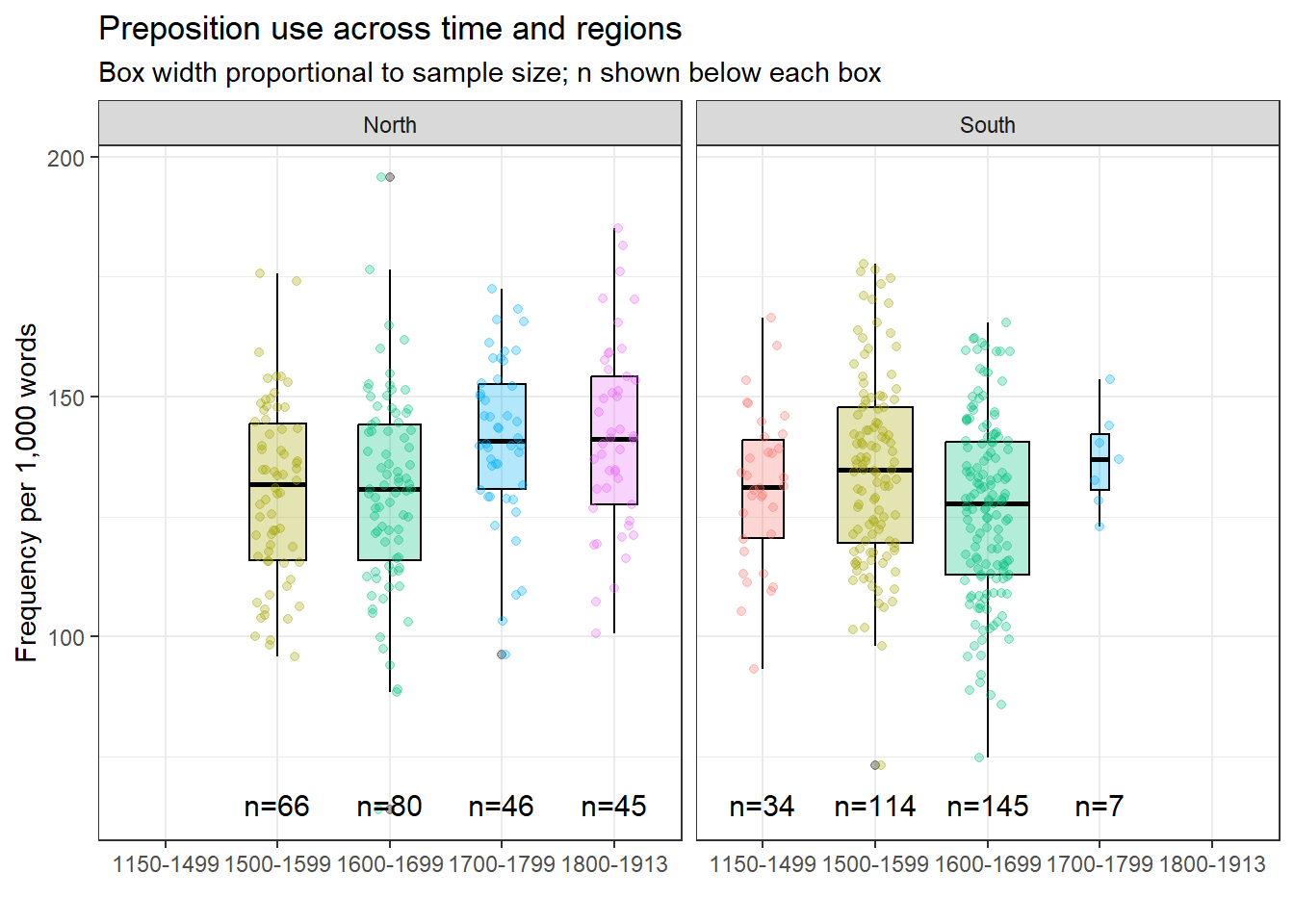
Enhanced boxplots with jittered points
Overlaying the individual data points on the boxplot reveals the sample size and distribution simultaneously.
Code
ggplot(pdat, aes(DateRedux, Prepositions, fill = DateRedux, color = DateRedux)) +geom_boxplot(varwidth =TRUE, color ="black", alpha =0.3) +geom_jitter(alpha =0.3, height =0, width =0.2) +facet_grid(~Region) + EnvStats::stat_n_text(y.pos =65) +theme_bw() +theme(legend.position ="none") +labs(x ="", y ="Frequency per 1,000 words",title ="Preposition use across time and regions",subtitle ="Box width proportional to sample size; n shown below each box")
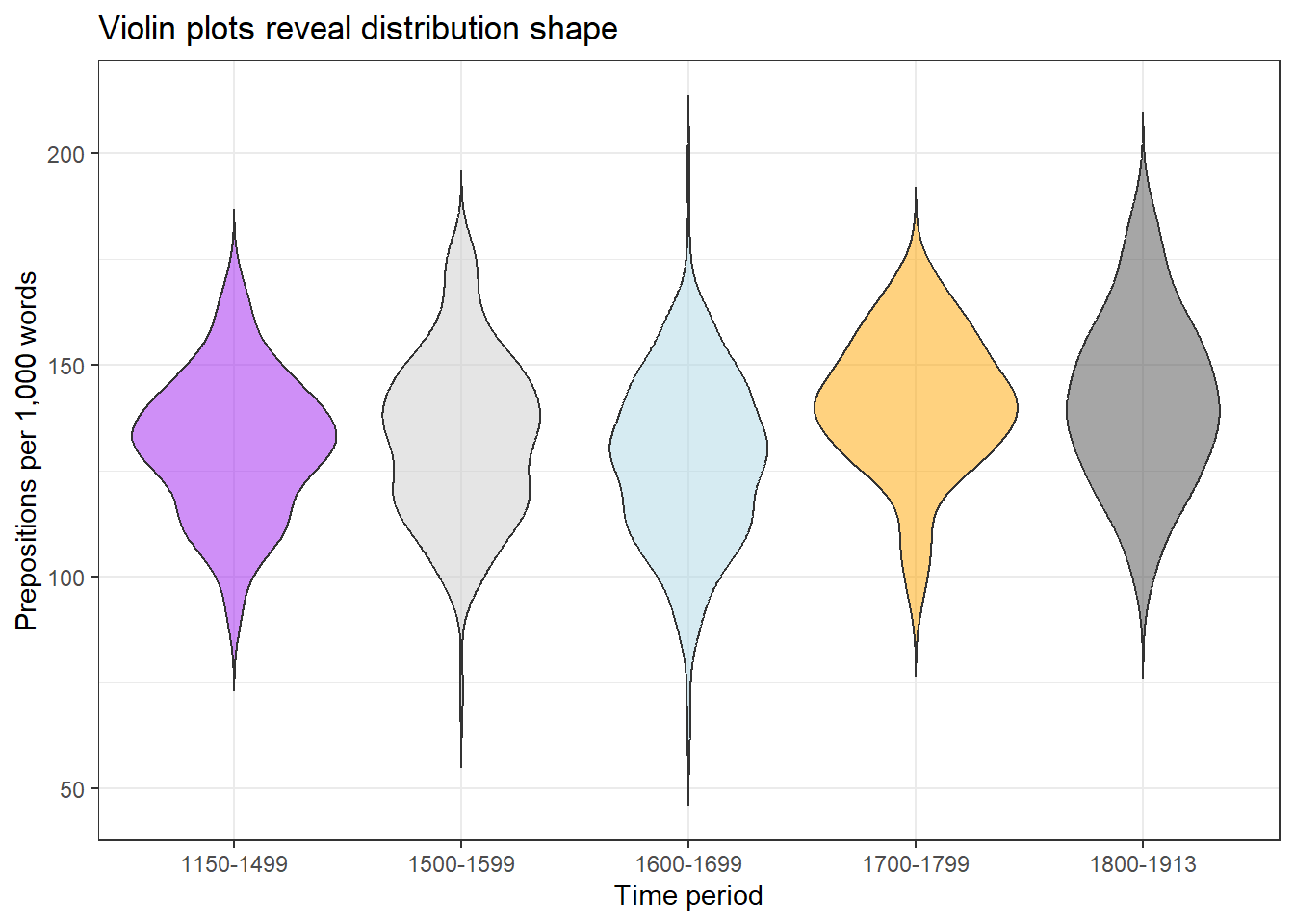
Violin plots
Violin plots mirror a density plot on both sides of a central axis, giving them their characteristic shape. They show the full distribution shape — including multimodality — while remaining compact enough to compare across groups.
Code
ggplot(pdat, aes(DateRedux, Prepositions, fill = DateRedux)) +geom_violin(trim =FALSE, alpha =0.5) +scale_fill_manual(values = clrs) +theme_bw() +theme(legend.position ="none") +labs(x ="Time period", y ="Prepositions per 1,000 words",title ="Violin plots reveal distribution shape")
Choosing between distribution plot types
Plot type
Reveals
Best for
Avoid when
Histogram
Counts in bins
Single variable, showing counts
Comparing many groups
Density
Smooth shape
Comparisons, overlapping groups
Exact counts needed
Ridge
Multiple shapes
Many groups (> 4)
Fewer than 3 groups
Boxplot
Five-number summary + outliers
Statistical summaries
Distribution shape matters
Violin
Shape + summary
Detecting multimodality
Very small samples
Part 4: Categorical Data
Section Overview
What you will learn: Bar plots in their basic, grouped, stacked, and normalised forms; Likert scale visualisation; and the case against pie charts
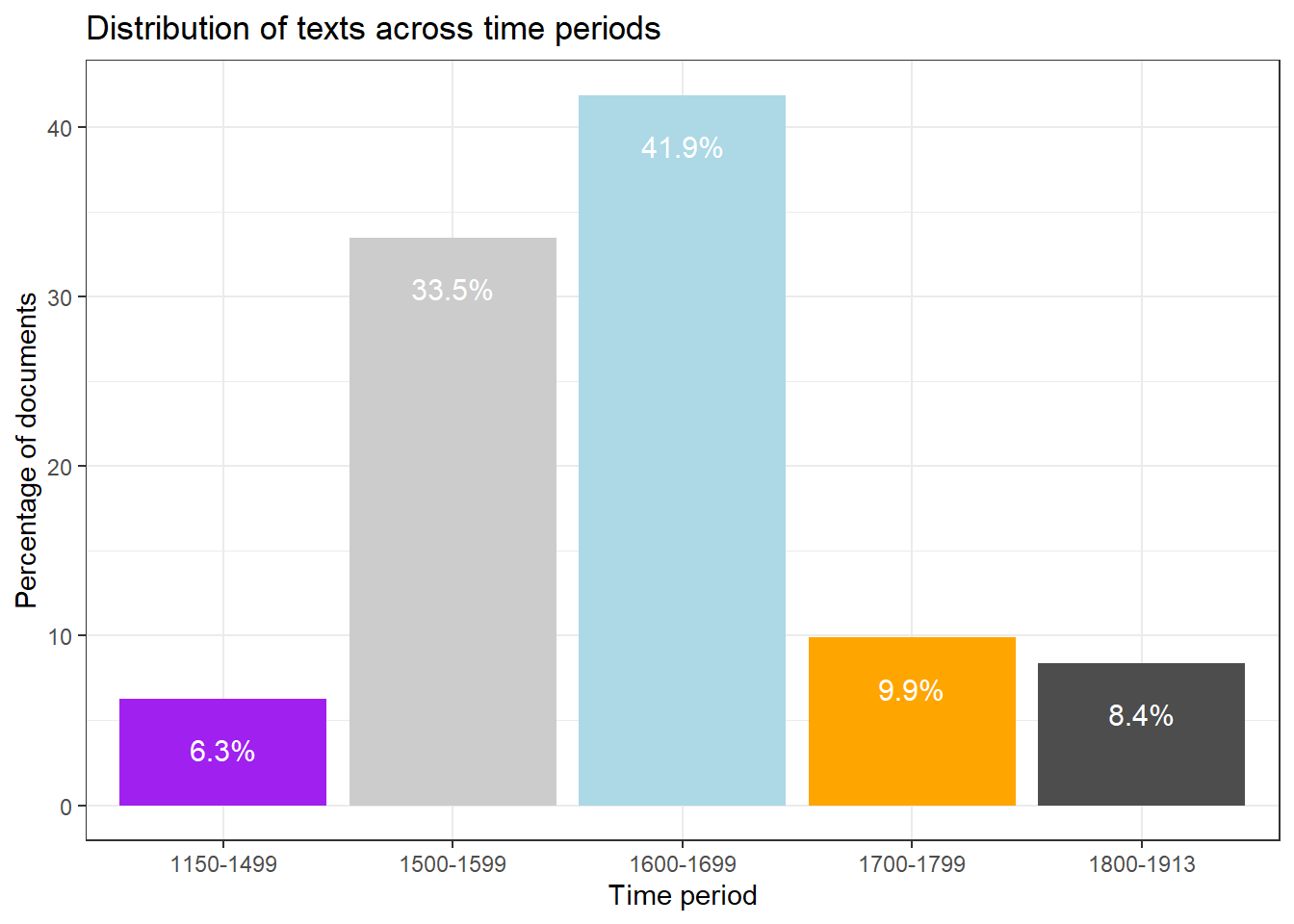
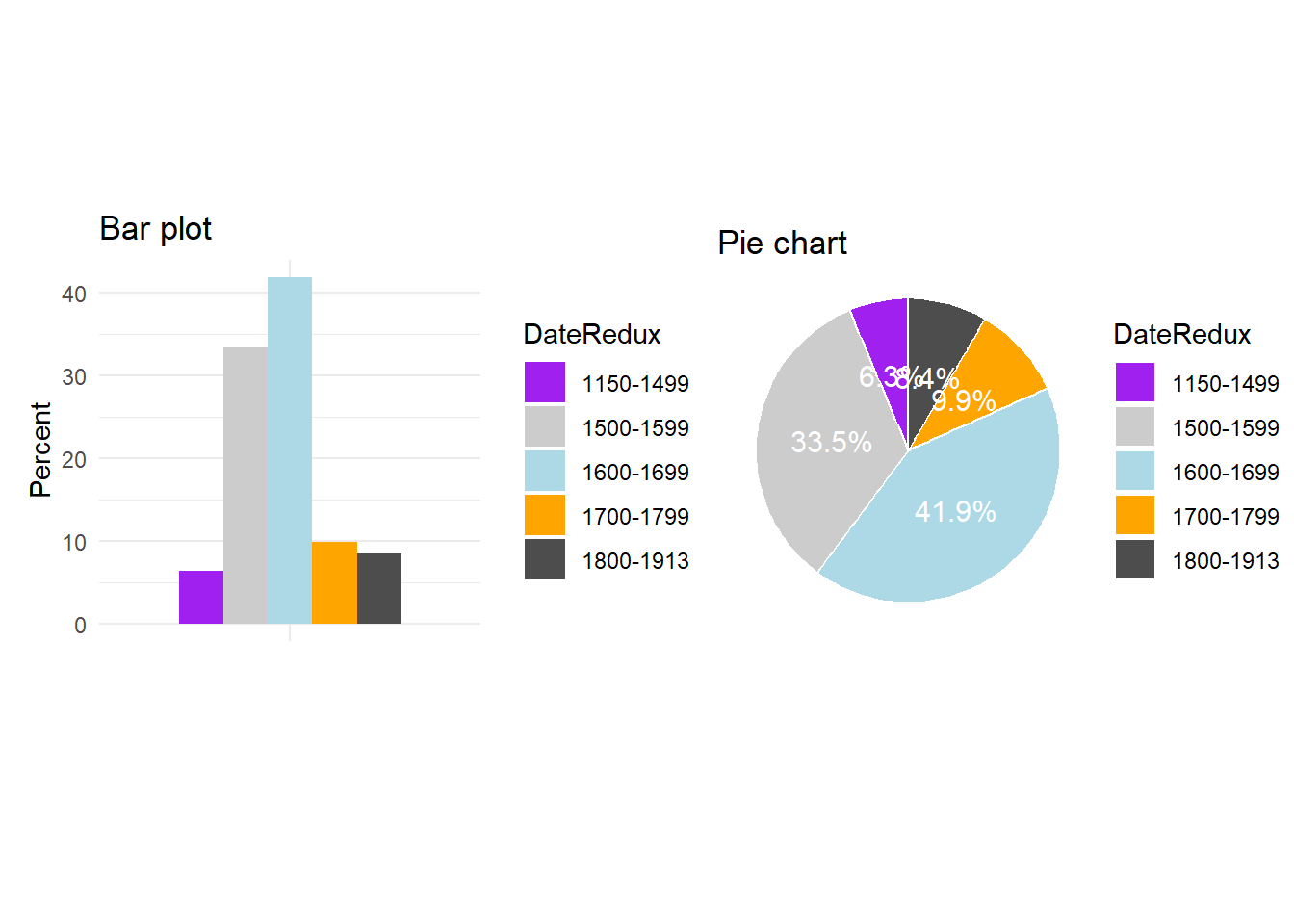
Bar plots
Bar plots show counts, frequencies, or summary values for categorical groups. They are the workhorse of categorical data visualisation.
ggplot(bdat, aes(DateRedux, Percent, fill = DateRedux)) +geom_bar(stat ="identity") +geom_text(aes(y = Percent -3,label =paste0(Percent, "%")),color ="white", size =4) +scale_fill_manual(values = clrs) +theme_bw() +theme(legend.position ="none") +labs(x ="Time period",y ="Percentage of documents",title ="Distribution of texts across time periods")
stat = "identity" explained
geom_bar() defaults to stat = "count", which counts the number of rows per group. When your data already contains the values to plot — as bdat$Percent does here — use stat = "identity" to plot the values as given without any additional aggregation.
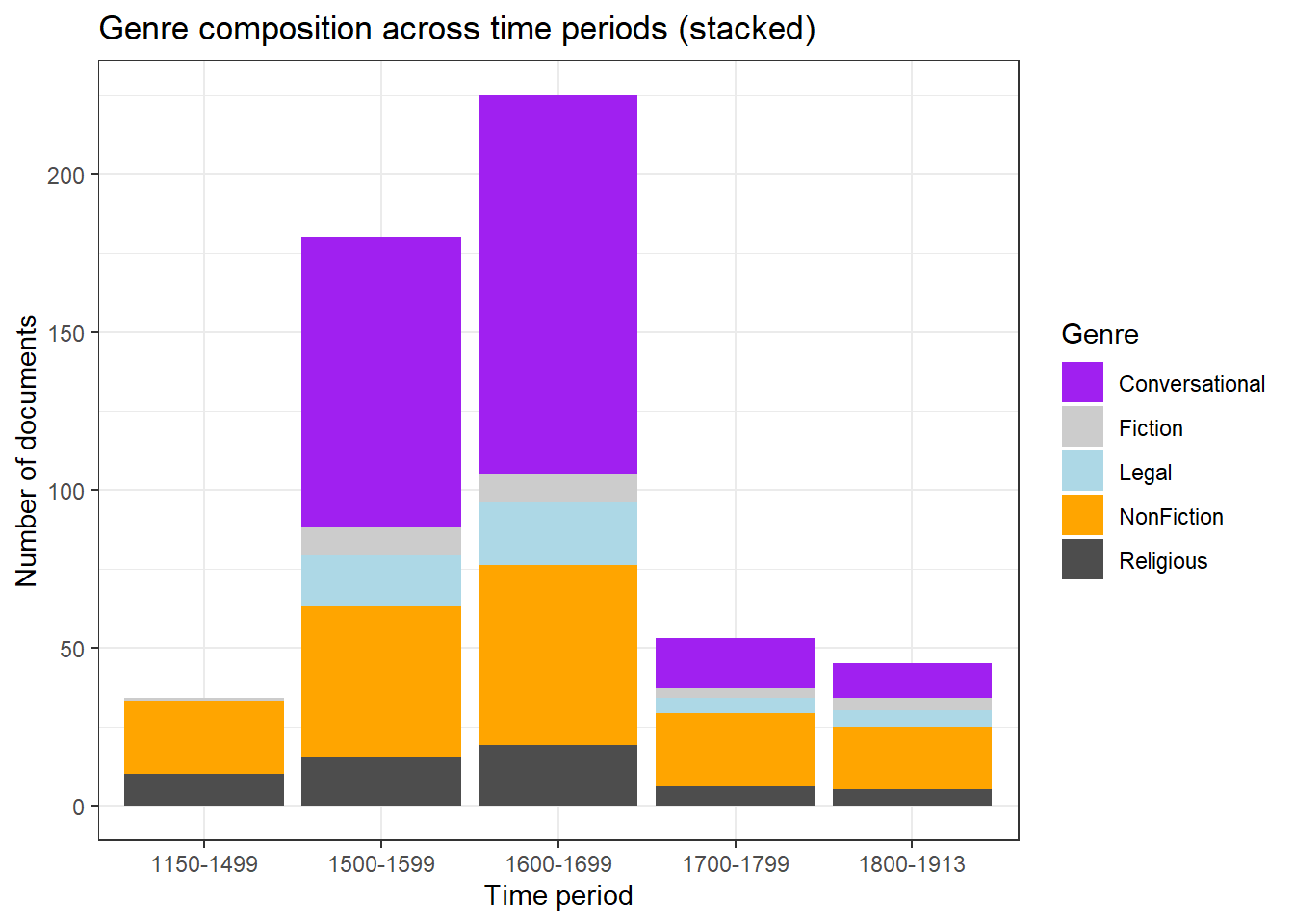
Grouped and stacked bar plots
Code
ggplot(pdat, aes(Region, fill = DateRedux)) +geom_bar(position =position_dodge(), stat ="count") +scale_fill_manual(values = clrs) +theme_bw() +labs(x ="Region", y ="Number of documents", fill ="Time period",title ="Document counts by region and time period (grouped)")
Code
ggplot(pdat, aes(DateRedux, fill = GenreRedux)) +geom_bar(stat ="count") +scale_fill_manual(values = clrs) +theme_bw() +labs(x ="Time period", y ="Number of documents", fill ="Genre",title ="Genre composition across time periods (stacked)")
Code
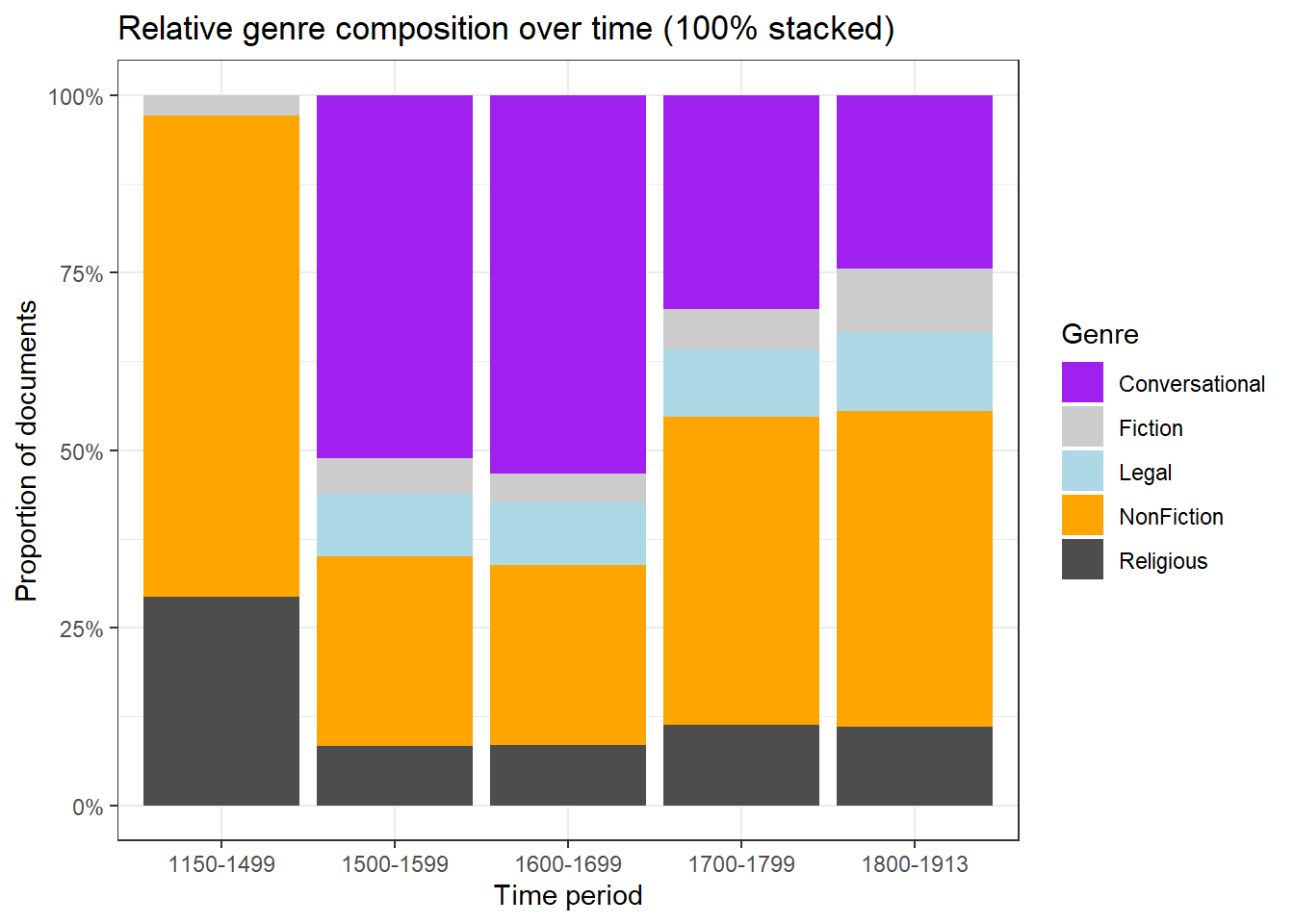
ggplot(pdat, aes(DateRedux, fill = GenreRedux)) +geom_bar(stat ="count", position ="fill") +scale_fill_manual(values = clrs) +scale_y_continuous(labels = scales::percent) +theme_bw() +labs(x ="Time period", y ="Proportion of documents", fill ="Genre",title ="Relative genre composition over time (100% stacked)")
Bar type
Use when
Basic / grouped
Comparing absolute counts across groups
Stacked
Showing composition and total simultaneously
100% normalised
Only proportions matter, not absolute counts
Likert scale visualisations
Survey data recorded on Likert scales (e.g. Strongly Disagree to Strongly Agree) requires careful visualisation because the response categories are ordered, the neutral midpoint is meaningful, and the visual emphasis should reflect valence.
A steeper slope at any point means responses are concentrated in that range. A line that runs high on the left means many dissatisfied respondents. When two lines cross, it means the distributions have different shapes — one group may have more extreme responses in both directions.
gglikert: diverging bar chart
The gglikert() function from the ggstats package creates diverging stacked bar charts that place negative responses on the left and positive responses on the right, with neutral in the middle. This is currently considered the most effective visualisation for Likert data.
Keep response categories in their natural order — never sort by frequency
Use a diverging colour palette (e.g. red–blue) centred on the neutral midpoint
Show the neutral category separately in the middle of the bar
Include sample sizes when comparing groups
Prefer diverging bar charts over plain stacked bars for communication
Pie charts: use with caution
The case against pie charts
Human visual perception is much better at comparing lengths (bar plot) than angles or areas (pie chart). Research consistently shows that people make more accurate judgements from bar charts than from pie charts, especially when slices are of similar size or when there are more than three categories.
Pie charts may be acceptable when there are only two or three categories and one clearly dominates. In most other situations, a bar chart communicates more accurately.
Without looking at the percentage labels, try to identify the second-largest category in each plot. The bar plot makes this easy; the pie chart makes it difficult.
Part 5: Advanced Visualisations
Section Overview
What you will learn: Heatmaps and association plots for matrix data; word clouds for text data; flag plots for international comparisons; dot plots with error bars; and diverging bar plots
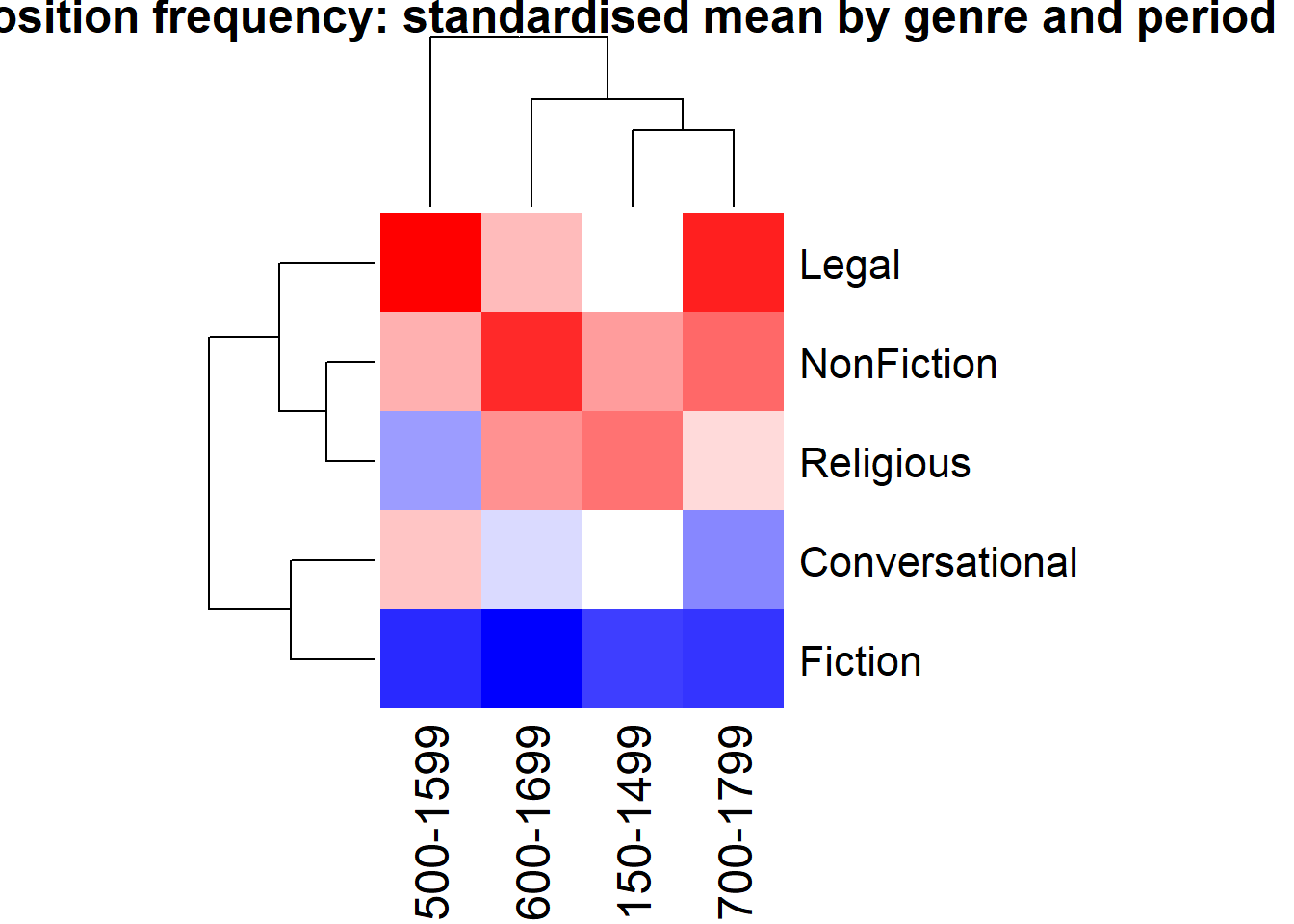
Heatmaps
Heatmaps use colour intensity to represent values in a two-dimensional matrix. They are effective for showing patterns across many combinations of two categorical variables.
heatmap(heatmx_scaled,scale ="none",col =colorRampPalette(c("blue", "white", "red"))(50),margins =c(7, 10),main ="Preposition frequency: standardised mean by genre and period")
The dendrograms show which genres (rows) and time periods (columns) cluster together based on their preposition frequency profiles. Blue indicates below-average frequency; red indicates above-average frequency.
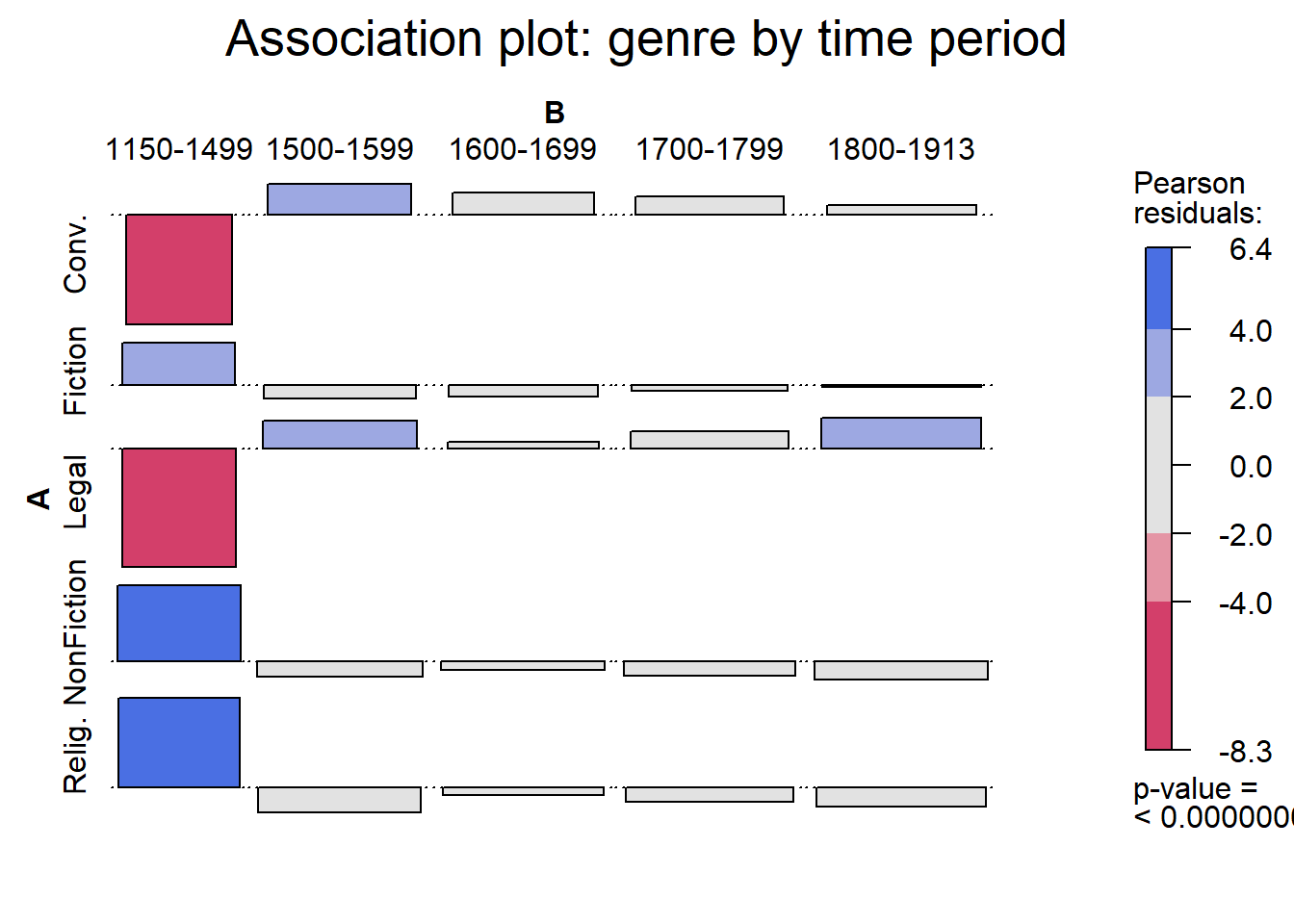
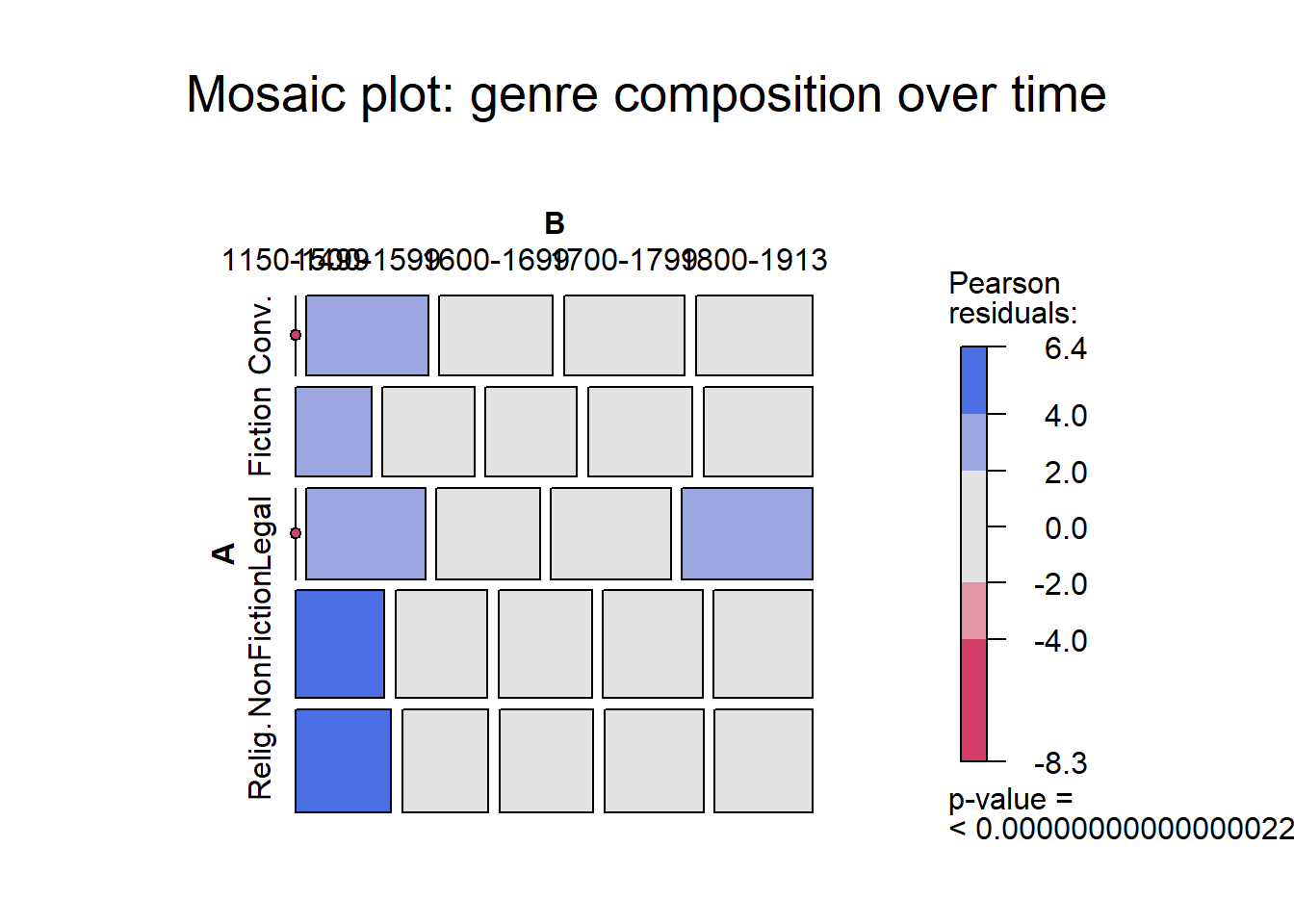
Association and mosaic plots
Association plots and mosaic plots from the vcd package visualise the relationship between two categorical variables, showing deviations from statistical independence.
Bars or tiles above the baseline: more than expected under independence
Bars or tiles below the baseline: less than expected
Blue shading: significantly more than expected (p < 0.05)
Red shading: significantly less than expected (p < 0.05)
Bar width in the association plot: contribution to the chi-square statistic
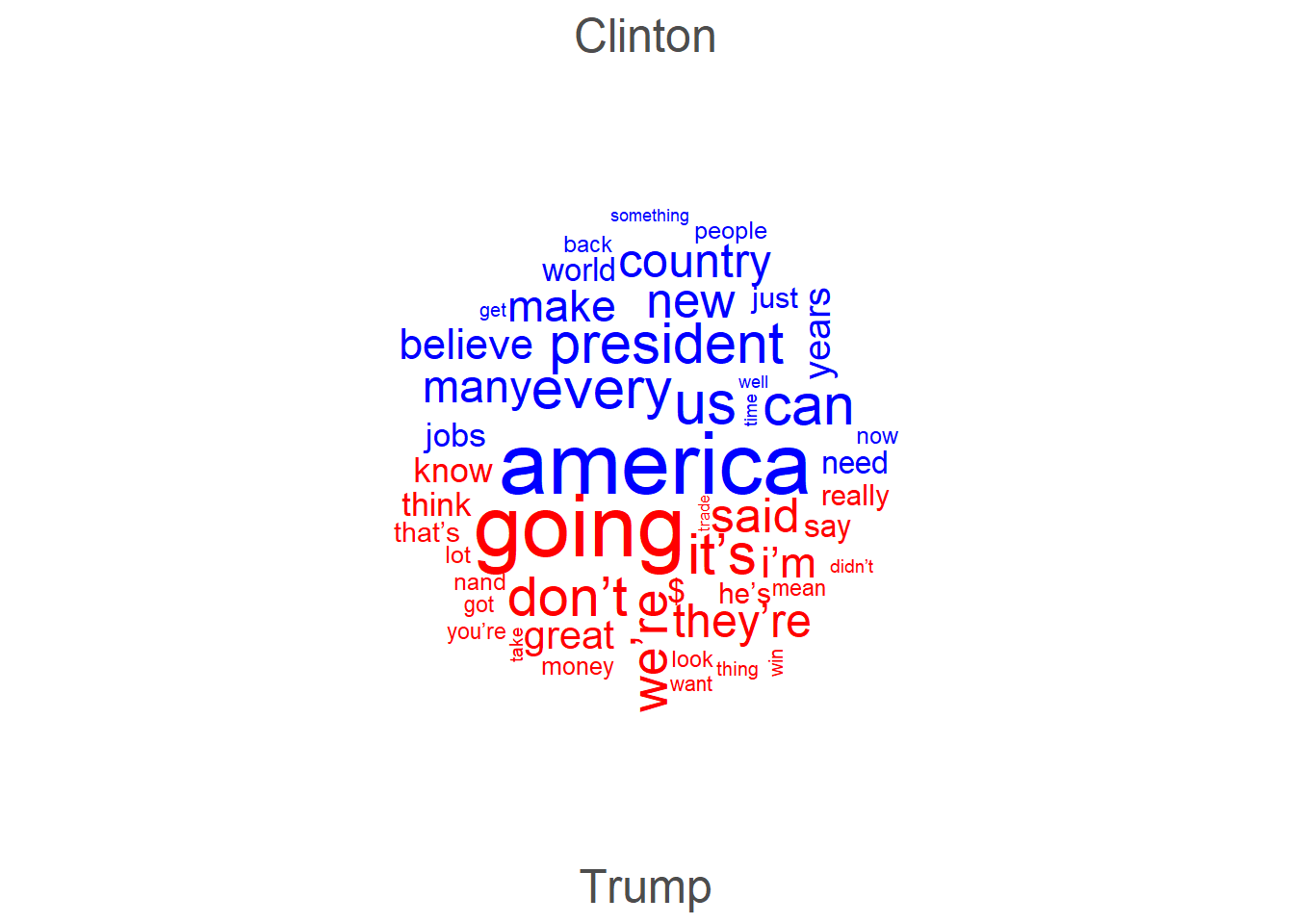
Word clouds
Word clouds represent term frequencies visually, with word size proportional to frequency. They are visually engaging but imprecise — word sizes are difficult to compare accurately. Use them for exploratory purposes or presentations, not as primary evidence in a paper.
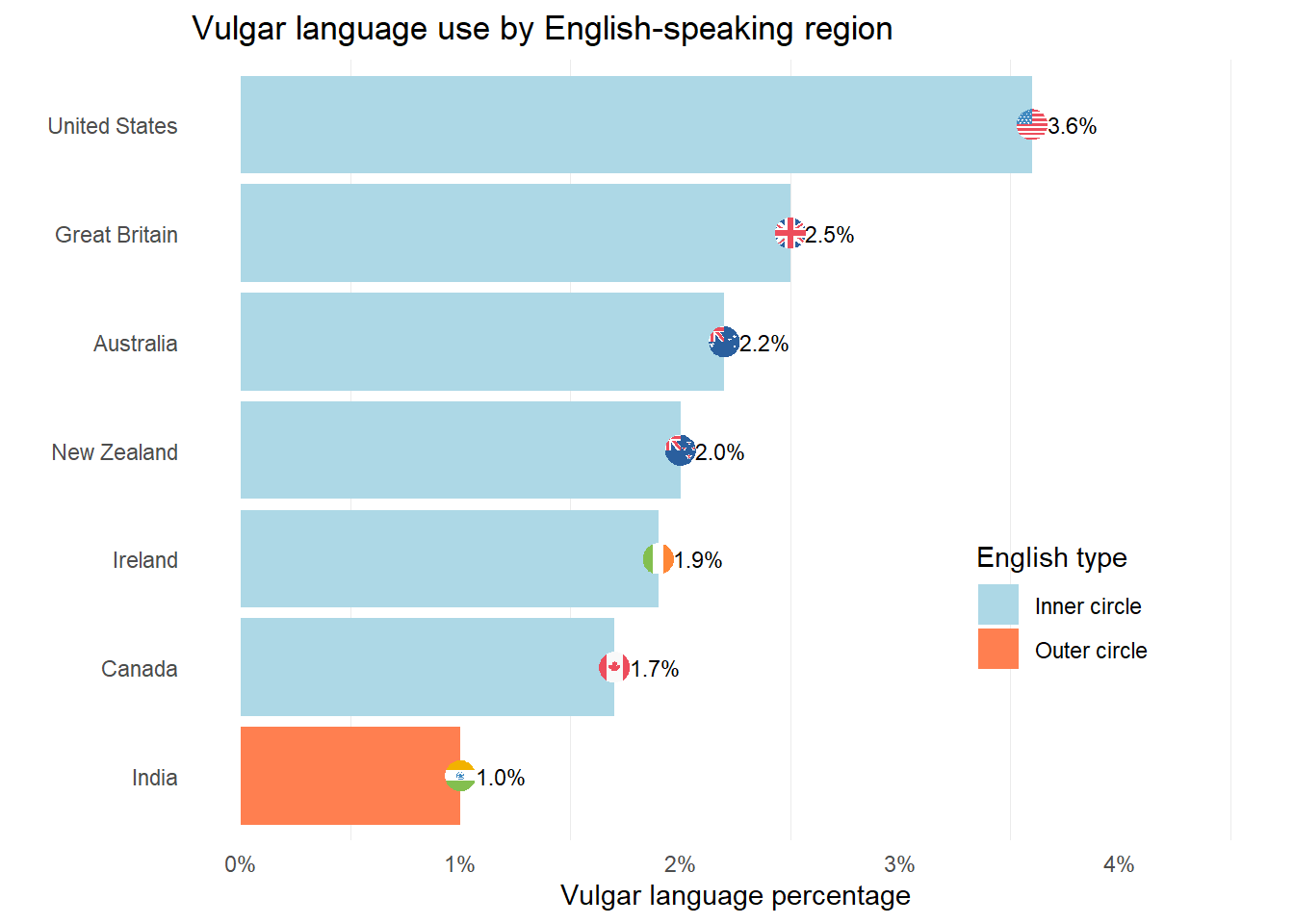
Dot plots showing means with confidence intervals are often preferable to bar plots for continuous outcomes because they avoid the visual distortion caused by showing the mean as the height of a bar that starts at zero.
Diverging bar plots show deviation from a reference value, with positive deviations extending in one direction and negative in the other. They are useful for comparing group profiles against a baseline.
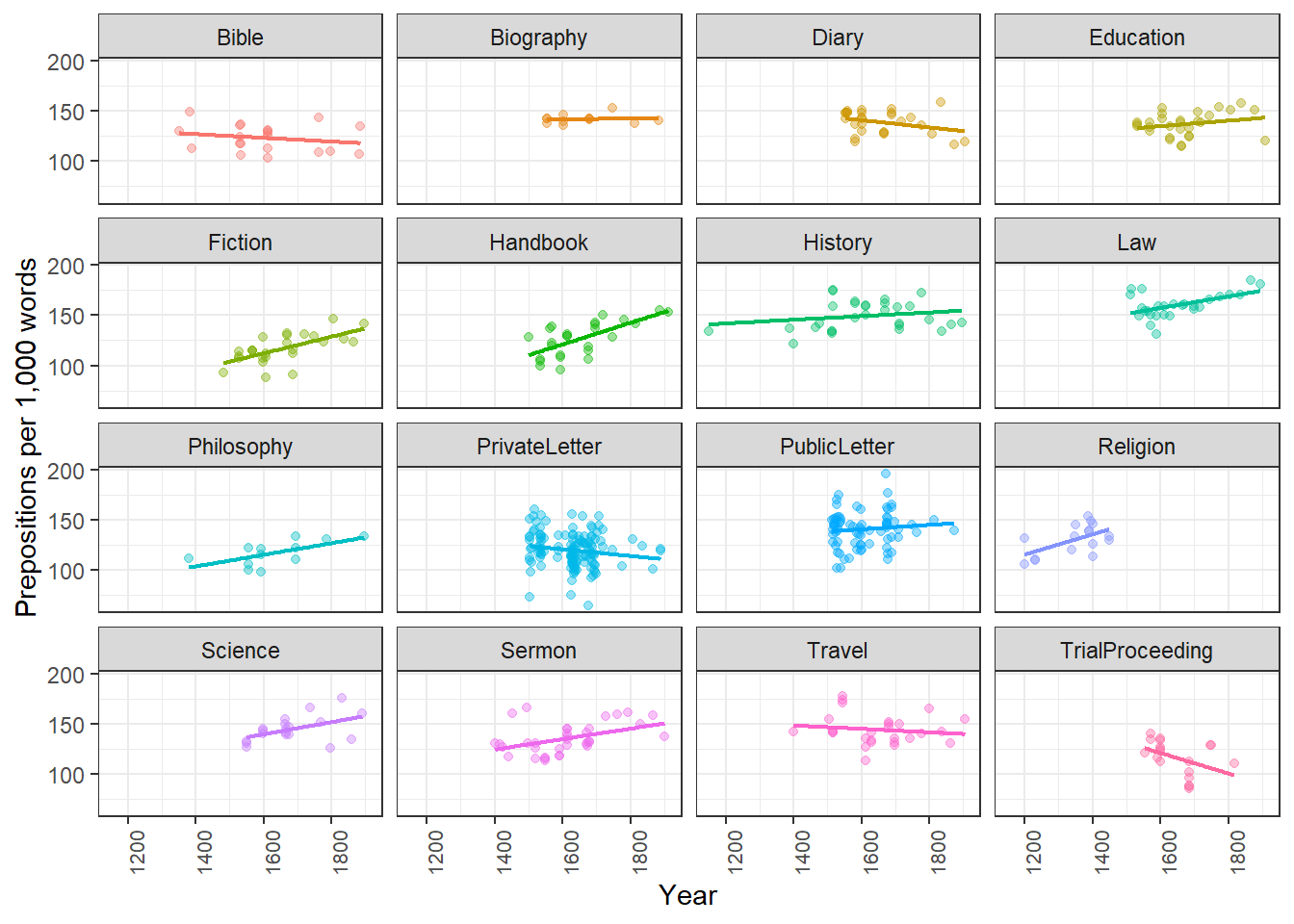
What you will learn: Line graphs for discrete and continuous time variables; smoothed trend lines; ribbon plots for displaying uncertainty; and how to choose between these approaches
Basic line graphs
Line graphs connect data points in temporal order, making trends and trajectories visible. The group aesthetic tells ggplot2 which points to connect.
Code
pdat |> dplyr::group_by(DateRedux, GenreRedux) |> dplyr::summarise(Frequency =mean(Prepositions), .groups ="drop") |>ggplot(aes(x = DateRedux, y = Frequency,group = GenreRedux,color = GenreRedux)) +geom_line(linewidth =1.2) +geom_point(size =3) +scale_color_manual(values = clrs) +theme_minimal() +labs(title ="Preposition frequency over time by genre",x ="Time period",y ="Mean frequency per 1,000 words",color ="Genre")
Smoothed line graphs
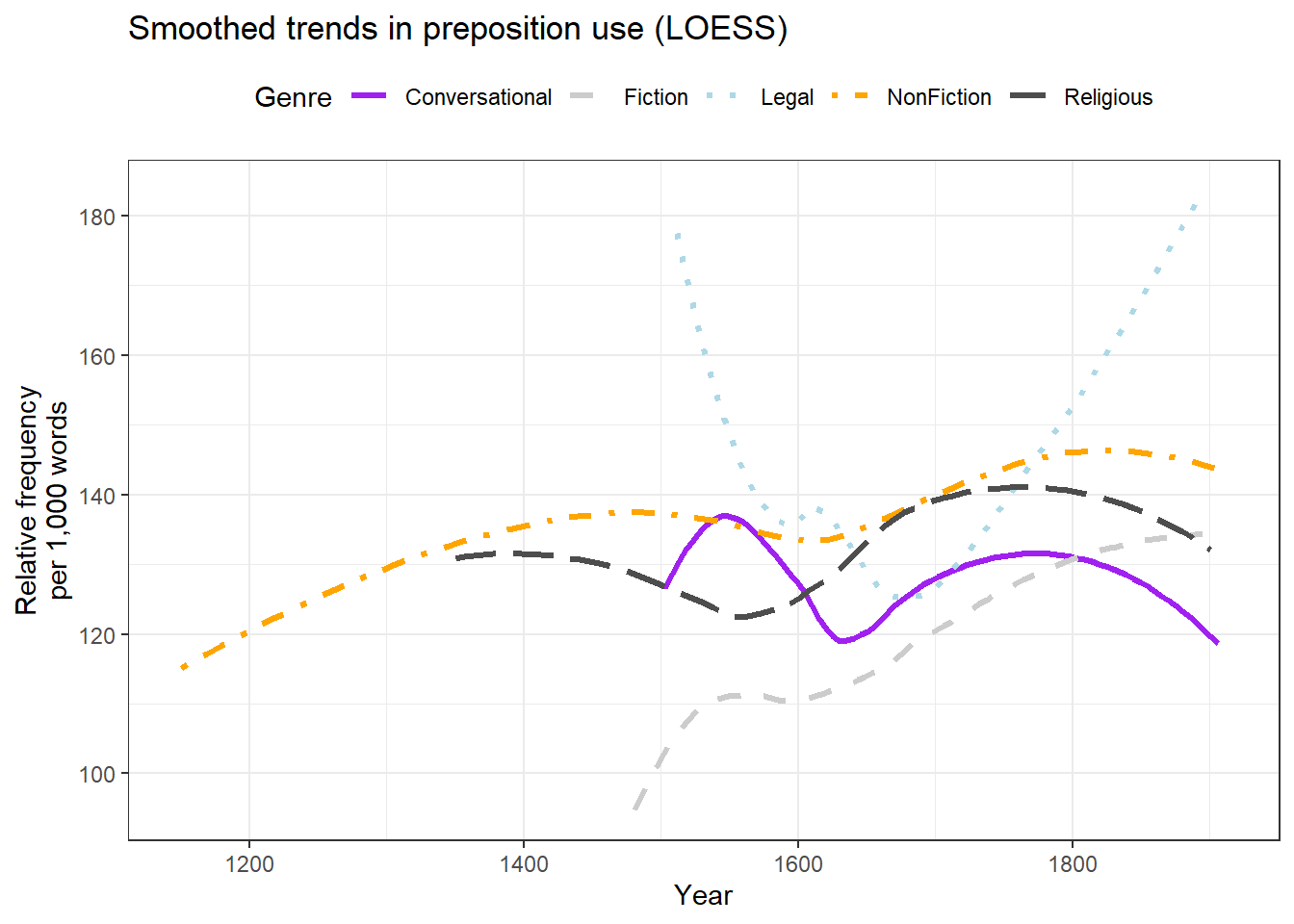
For continuous time variables with many data points, LOESS smoothing (locally estimated scatterplot smoothing) reveals the underlying trend while absorbing noise from individual observations.
Code
ggplot(pdat, aes(x = Date, y = Prepositions,color = GenreRedux,linetype = GenreRedux)) +geom_smooth(se =FALSE, linewidth =1.2) +scale_linetype_manual(values =c("solid", "dashed", "dotted", "dotdash", "longdash"),name ="Genre" ) +scale_colour_manual(values = clrs, name ="Genre") +theme_bw() +theme(legend.position ="top") +labs(x ="Year", y ="Relative frequency\nper 1,000 words",title ="Smoothed trends in preposition use (LOESS)")
Using both colour and line type (redundant encoding) keeps the lines distinguishable in greyscale and for readers with colour vision deficiency.
Ribbon plots: showing uncertainty
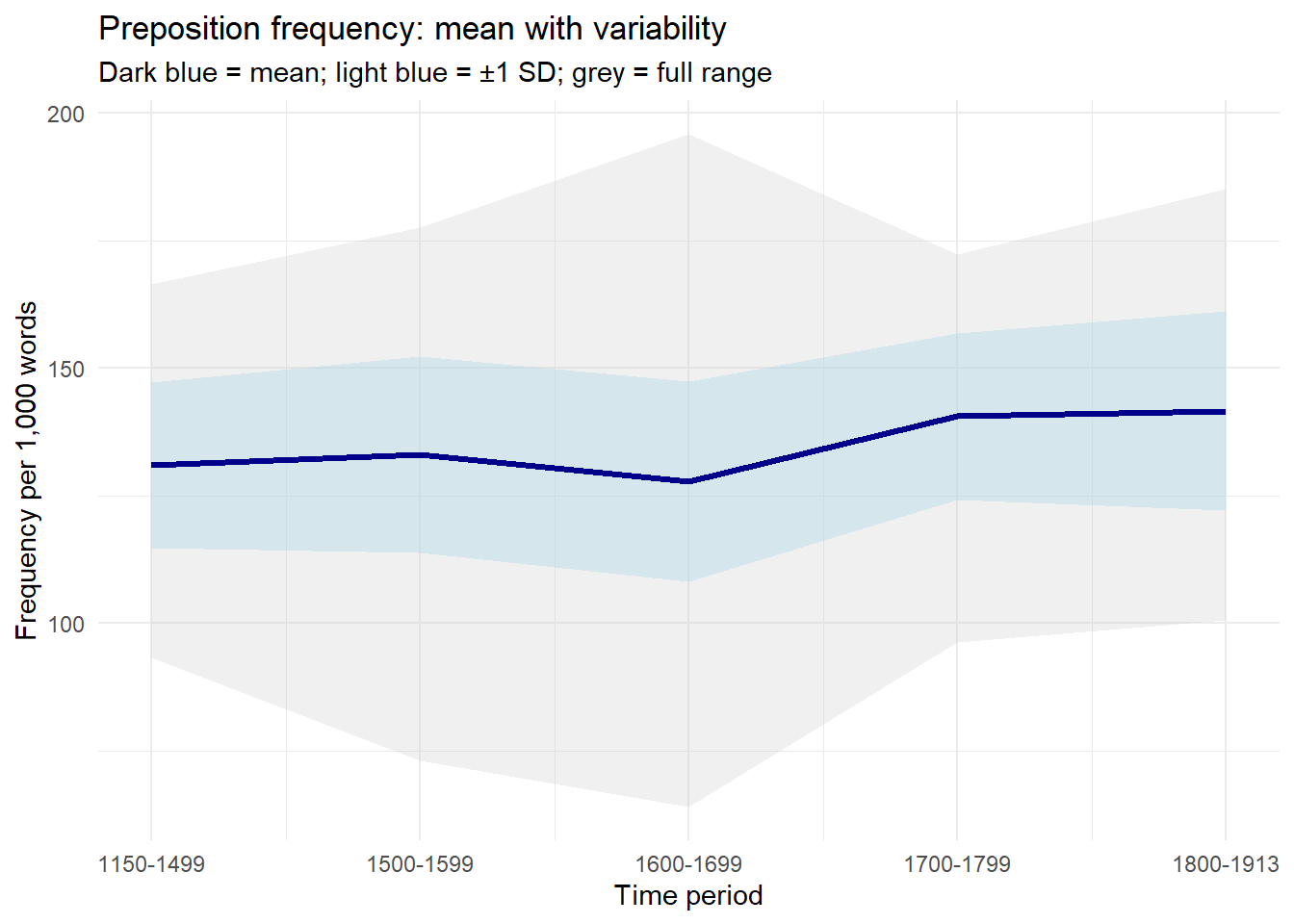
Ribbon plots (geom_ribbon) display ranges or intervals as shaded bands around a central line. They are effective for communicating uncertainty, variability, or the full range of observed values.
Code
pdat |> dplyr::mutate(DateRedux =as.numeric(DateRedux)) |> dplyr::group_by(DateRedux) |> dplyr::summarise(Mean =mean(Prepositions),Min =min(Prepositions),Max =max(Prepositions),SD =sd(Prepositions),.groups ="drop" ) |>ggplot(aes(x = DateRedux, y = Mean)) +geom_ribbon(aes(ymin = Min, ymax = Max),fill ="gray80", alpha =0.3) +geom_ribbon(aes(ymin = Mean - SD, ymax = Mean + SD),fill ="lightblue", alpha =0.4) +geom_line(linewidth =1.2, color ="darkblue") +scale_x_continuous(labels =names(table(pdat$DateRedux))) +theme_minimal() +labs(title ="Preposition frequency: mean with variability",subtitle ="Dark blue = mean; light blue = ±1 SD; grey = full range",x ="Time period",y ="Frequency per 1,000 words")
Part 7: Combining Plots with patchwork
Section Overview
What you will learn: How to combine multiple ggplot2 plots into a single figure using the patchwork package; layout operators; adding shared titles, subtitles, and labels; and when combining plots is appropriate
Why combine plots?
A multi-panel figure is often more effective than a series of separate plots when:
You want readers to compare related results side by side
A single visualisation cannot show all the relevant aspects of the data
You are preparing a figure for a publication that expects one figure file per result
The patchwork package provides a simple and powerful syntax for combining ggplot2 plots.
Basic patchwork syntax
The three main operators are:
| — place plots side by side (horizontal)
/ — place plots one above the other (vertical)
+ — add to the current layout (follows row-by-row order)
() — group plots for nested layouts
Code
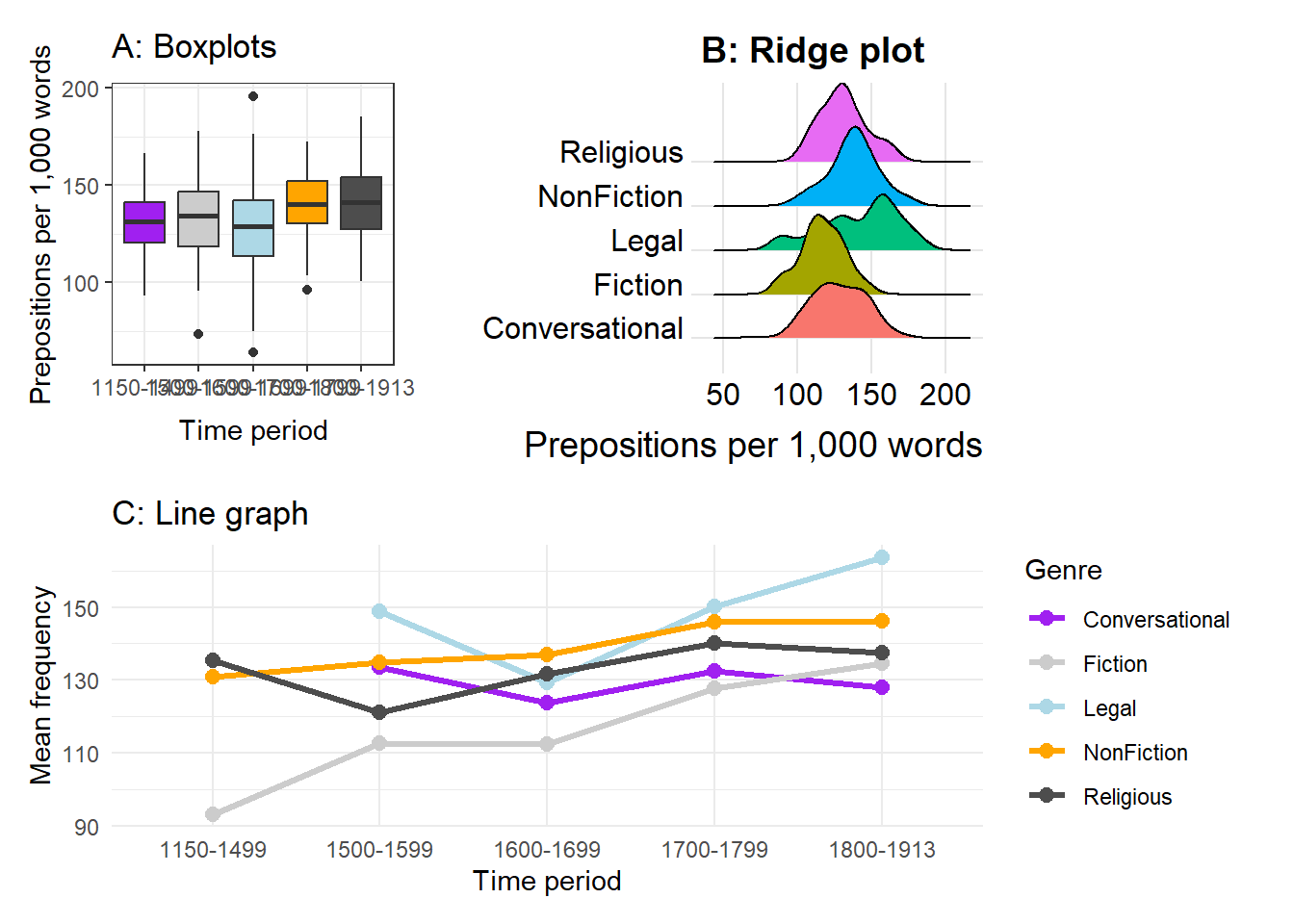
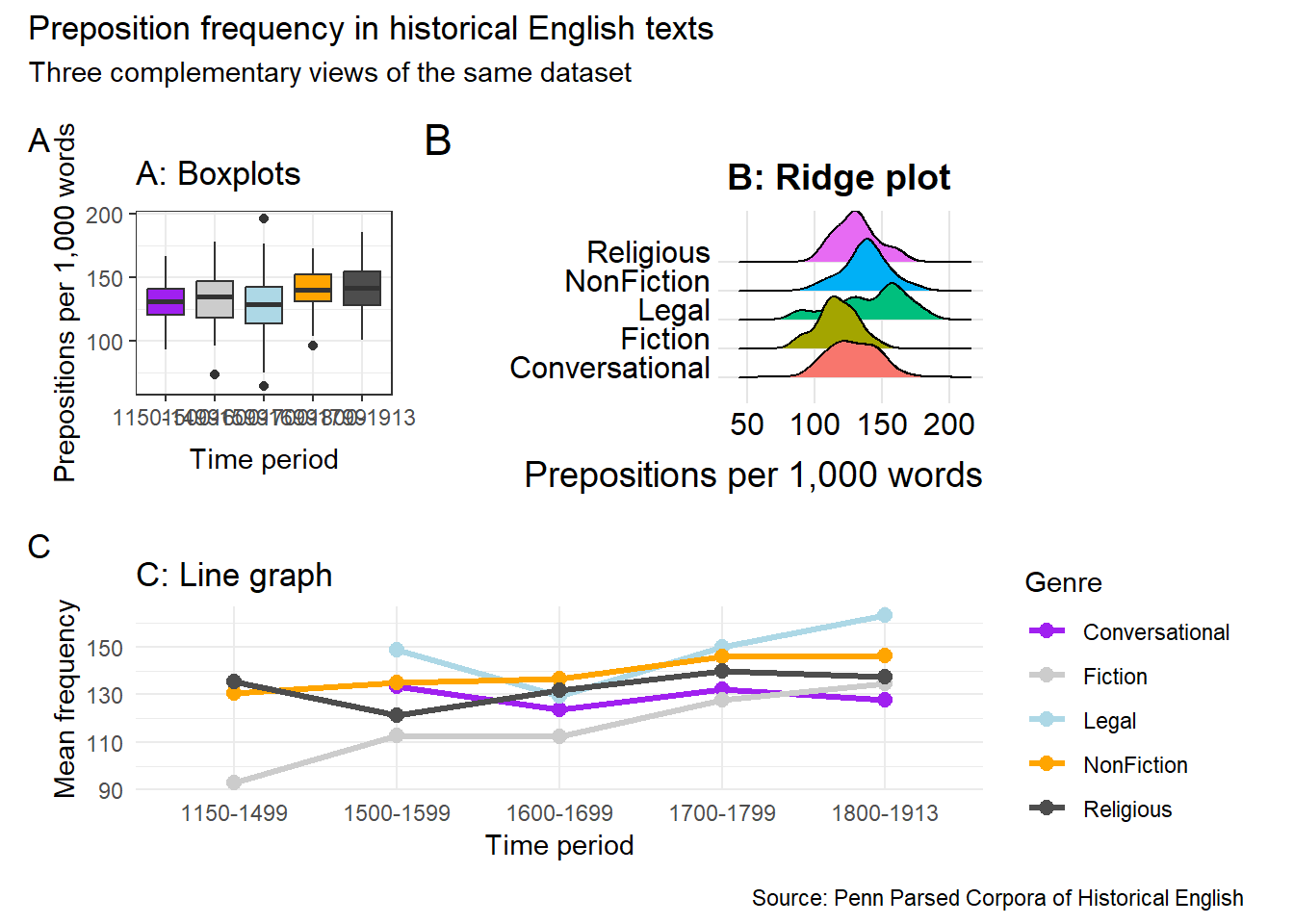
# Create three component plotsp1 <-ggplot(pdat, aes(x = DateRedux, y = Prepositions, fill = DateRedux)) +geom_boxplot() +scale_fill_manual(values = clrs) +theme_bw() +theme(legend.position ="none") +labs(x ="Time period", y ="Prepositions per 1,000 words",title ="A: Boxplots")p2 <-ggplot(pdat, aes(x = Prepositions, y = GenreRedux, fill = GenreRedux)) +geom_density_ridges() +theme_ridges() +theme(legend.position ="none") +labs(x ="Prepositions per 1,000 words", y ="",title ="B: Ridge plot")p3 <- pdat |> dplyr::group_by(DateRedux, GenreRedux) |> dplyr::summarise(Mean =mean(Prepositions), .groups ="drop") |>ggplot(aes(x = DateRedux, y = Mean,group = GenreRedux, color = GenreRedux)) +geom_line(linewidth =1.1) +geom_point(size =2.5) +scale_color_manual(values = clrs) +theme_minimal() +labs(x ="Time period", y ="Mean frequency",color ="Genre", title ="C: Line graph")# Combine: p1 and p2 side by side, with p3 below(p1 | p2) / p3
Shared labels and annotations
patchwork provides plot_annotation() for adding overall titles, subtitles, and captions, and plot_layout() for controlling spacing and shared legends.
Code
(p1 | p2) / p3 +plot_annotation(title ="Preposition frequency in historical English texts",subtitle ="Three complementary views of the same dataset",caption ="Source: Penn Parsed Corpora of Historical English",tag_levels ="A" )
Collecting legends
When multiple plots share the same colour mapping, you can collect the legends into a single shared legend with plot_layout(guides = "collect").
Code
pa <-ggplot(pdat, aes(DateRedux, Prepositions, fill = GenreRedux)) +geom_boxplot() +scale_fill_manual(values = clrs) +theme_bw() +labs(x ="Time period", y ="Prepositions", fill ="Genre")pb <-ggplot(pdat, aes(DateRedux, fill = GenreRedux)) +geom_bar(position ="fill") +scale_fill_manual(values = clrs) +scale_y_continuous(labels = scales::percent) +theme_bw() +labs(x ="Time period", y ="Proportion", fill ="Genre")pa2 <- pa +theme(legend.position ="bottom")pb2 <- pb +theme(legend.position ="bottom")pa2 | pb2
Part 8: Publication-Ready Plots and Choosing Wisely
Section Overview
What you will learn: What makes a plot publication-ready; saving figures in the right format and resolution; colour accessibility; a decision framework for choosing plot types; and the most common visualisation mistakes to avoid
The anatomy of a publication-ready plot
A plot ready for a journal article or conference proceedings should have:
A clear, informative title and (where appropriate) a subtitle
Axis labels that name the variable and include units
A legend that is necessary and clearly positioned
A theme appropriate to the publication context (usually theme_bw() or theme_minimal() rather than the default grey background)
Font sizes large enough to be legible at the final printed size
A colourblind-accessible colour palette
A caption noting the data source and what error bars or ribbons represent
Complete example
Code
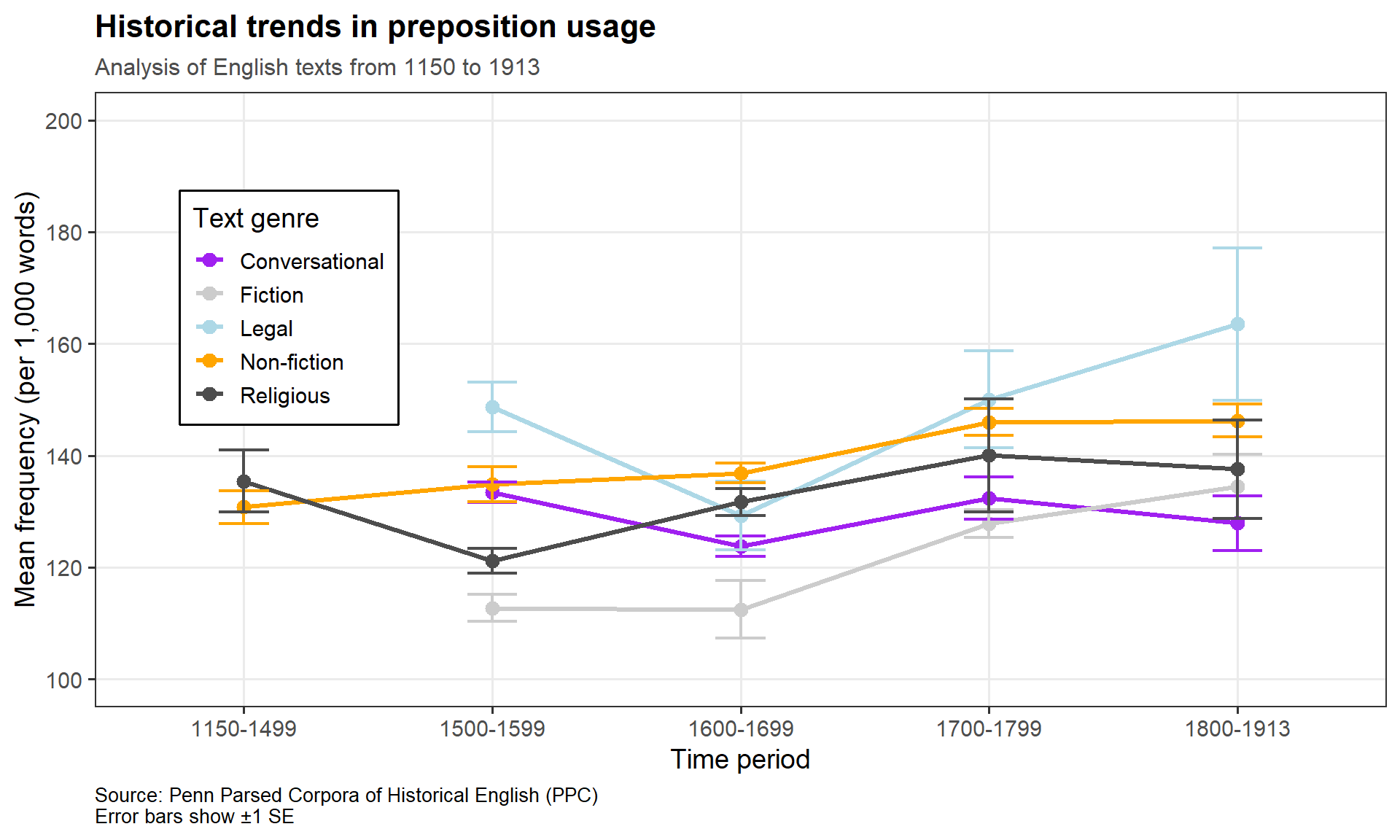
pdat |> dplyr::group_by(DateRedux, GenreRedux) |> dplyr::summarise(Mean =mean(Prepositions),SE =sd(Prepositions) /sqrt(n()),N =n(),.groups ="drop" ) |>ggplot(aes(x = DateRedux, y = Mean,color = GenreRedux, group = GenreRedux)) +geom_line(linewidth =1.2) +geom_point(size =3) +geom_errorbar(aes(ymin = Mean - SE, ymax = Mean + SE),width =0.2, linewidth =0.8) +scale_color_manual(name ="Text genre",values = clrs,labels =c("Conversational", "Fiction", "Legal", "Non-fiction", "Religious") ) +scale_y_continuous(breaks =seq(100, 200, 20), limits =c(100, 200)) +theme_bw(base_size =14) +theme(legend.position =c(0.15, 0.65),legend.background =element_rect(fill ="white", color ="black"),panel.grid.minor =element_blank(),plot.title =element_text(face ="bold", size =16),plot.subtitle =element_text(size =12, color ="gray30"),plot.caption =element_text(size =10, hjust =0) ) +labs(title ="Historical trends in preposition usage",subtitle ="Analysis of English texts from 1150 to 1913",x ="Time period",y ="Mean frequency (per 1,000 words)",caption ="Source: Penn Parsed Corpora of Historical English (PPC)\nError bars show ±1 SE" )
Saving figures
Code
# For journal submission (300 dpi minimum)ggsave("preposition_trends.png", width =10, height =6, dpi =300)# For vector graphics (no resolution limit — scales to any size)ggsave("preposition_trends.pdf", width =10, height =6)# For web useggsave("preposition_trends_web.png", width =10, height =6, dpi =150)
Format guide
PNG — raster format; use for web, slides, and figures containing photographs. Specify dpi = 300 for print.
PDF — vector format; use for journal submission where possible. Scales to any size without loss of quality. Best for plots containing text and sharp geometric elements.
TIFF — some journals require TIFF. Use dpi = 600 for posters.
SVG — vector format; useful for web and for figures you may need to edit further in Inkscape or Illustrator.
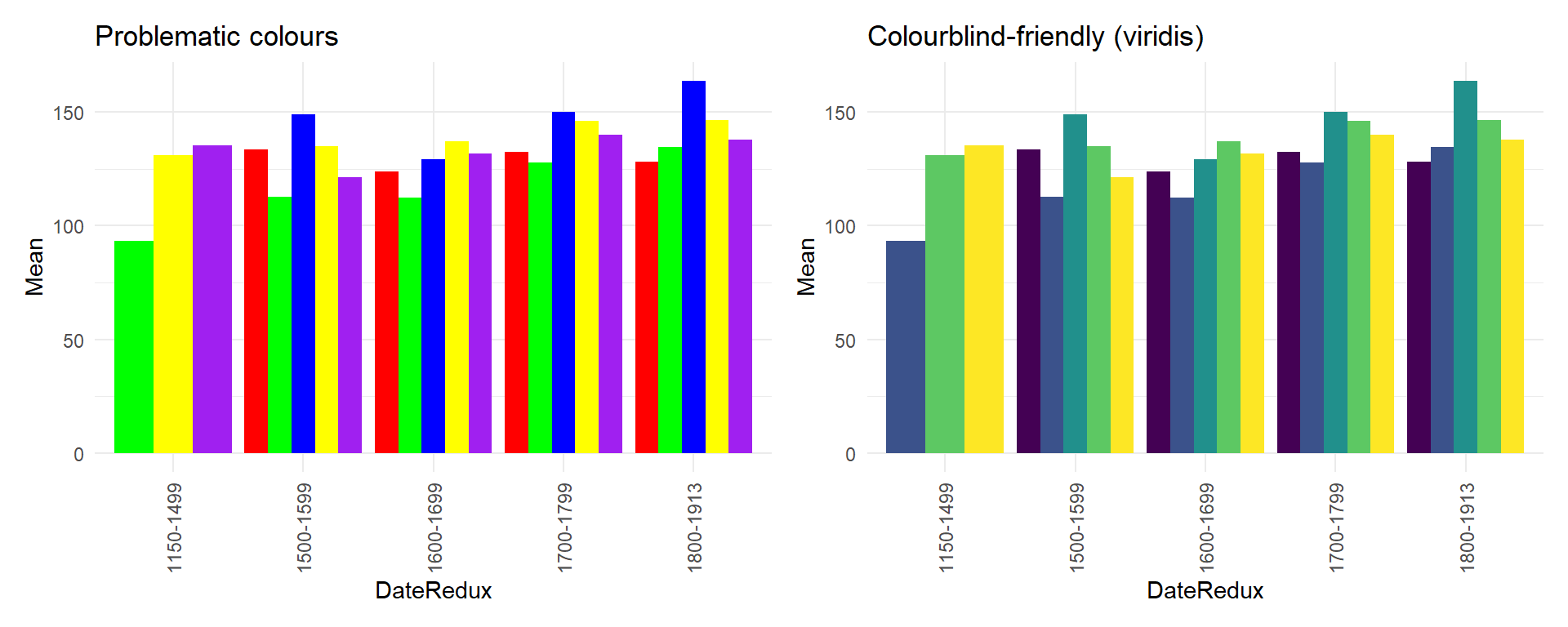
Colour accessibility
Approximately 8% of men and 0.5% of women have some form of colour vision deficiency. Designing accessible plots benefits all readers, not only those with colour vision differences.
scale_color_viridis_d() / scale_fill_viridis_d() — for discrete variables
scale_color_viridis_c() / scale_fill_viridis_c() — for continuous variables
scale_color_brewer(palette = "Set2") or "Dark2" — ColorBrewer palettes, many colourblind-safe
Redundant encoding (colour + shape, or colour + line type) as a complement
Choosing the right plot: a decision framework
By data structure
One continuous variable — show distribution:
Small samples (< 50): dot plot, strip plot
Medium samples (50–500): histogram, density plot
Large samples (500+): density plot, violin plot
Summary statistics: boxplot
One continuous + one categorical — compare groups:
Distributions: boxplot, violin plot, ridge plot
Means with uncertainty: dot plot with error bars
Show all data: jittered points
Two continuous variables — show relationship:
Basic: scatter plot
Overplotting: hex plot, 2D density
With trend: add geom_smooth()
Groups: colour, shape, or facets
Two categorical variables — show association:
Frequencies: grouped or stacked bar plot
Proportions: 100% normalised bar, mosaic plot
Statistical deviations: association plot
Time series — show change:
Discrete time points: line graph with points
Continuous time: smoothed line, ribbon plot
Multiple series: coloured lines or small multiples
Three or more variables — multivariate:
Third variable categorical: colour + facets
Third variable continuous: colour gradient or bubble size
Many variables: heatmap
Common mistakes to avoid
3D charts — almost never appropriate. They distort values through perspective effects and make precise comparison impossible. Use 2D plots with grouping, colour, or facets instead.
Dual y-axes — can be used to misrepresent relationships between variables by independently scaling each axis. Prefer faceted plots or normalising both variables to the same scale.
Truncated y-axis on bar plots — bar heights encode values by length from zero. Cutting the axis at a non-zero value exaggerates differences. Bar plots must start at zero. Dot plots with error bars can use a truncated axis because they do not encode values by length from a baseline.
Too many colours — more than about six colours becomes difficult to distinguish. Consider reducing categories, using facets, or highlighting one group while greying the rest.
Chartjunk — decorative elements (unnecessary gridlines, 3D shadows, background images, clipart) distract from the data and add no information. Start with theme_minimal() or theme_bw() and add only what is needed.
Sorting bars randomly — unless the categories have a natural order (time periods, scale levels), sort bars by value to make rank comparisons easy.
Final Challenge: Capstone Project
Comprehensive data visualisation project
You have learned all the core techniques. The capstone is to create a coherent data story using the pdat dataset (or your own data).
Required components:
At least three different plot types from different sections — one showing distributions, one showing relationships, and one showing categorical comparisons
Publication-ready quality: proper titles, labels and captions; a colourblind-friendly palette; appropriate themes; clear legends
At least one combined figure using patchwork with a shared annotation
A written narrative: a short introduction explaining your research question; brief transition text between plots explaining what each shows; and a conclusion summarising what the visualisations reveal
Example research questions to explore:
How has genre composition changed across the historical periods covered in the corpus?
Are there regional differences in preposition frequency, and do they interact with time period?
Which genres show the greatest variability in preposition use, and what might this reflect about genre norms?
Suggested deliverables: A fully ggplot2::annotated .qmd document with all code, at least three saved publication-quality figures (PNG, 300 dpi), and a brief 2–3 sentence caption for each figure as it would appear in a paper.
Citation & Session Info
Citation
Martin Schweinberger. 2026. Mastering Data Visualization with R. The Language Technology and Data Analysis Laboratory (LADAL), The University of Queensland, Australia. url: https://ladal.edu.au/tutorials/data_viz_advanced/data_viz_advanced.html (Version 3.1.1). doi: 10.5281/zenodo.19332872.
@manual{martinschweinberger2026mastering,
author = {Martin Schweinberger},
title = {Mastering Data Visualization with R},
year = {2026},
note = {https://ladal.edu.au/tutorials/data_viz_advanced/data_viz_advanced.html},
organization = {The Language Technology and Data Analysis Laboratory (LADAL), The University of Queensland, Australia},
edition = {3.1.1}
doi = {10.5281/zenodo.19332872}
}
This tutorial was re-developed with the assistance of Claude (claude.ai), a large language model created by Anthropic. Claude was used to help revise the tutorial text, structure the instructional content, generate the R code examples, and write the checkdown quiz questions and feedback strings. All content was reviewed, edited, and approved by the author (Martin Schweinberger), who takes full responsibility for the accuracy and pedagogical appropriateness of the material. The use of AI assistance is disclosed here in the interest of transparency and in accordance with emerging best practices for AI-assisted academic content creation.