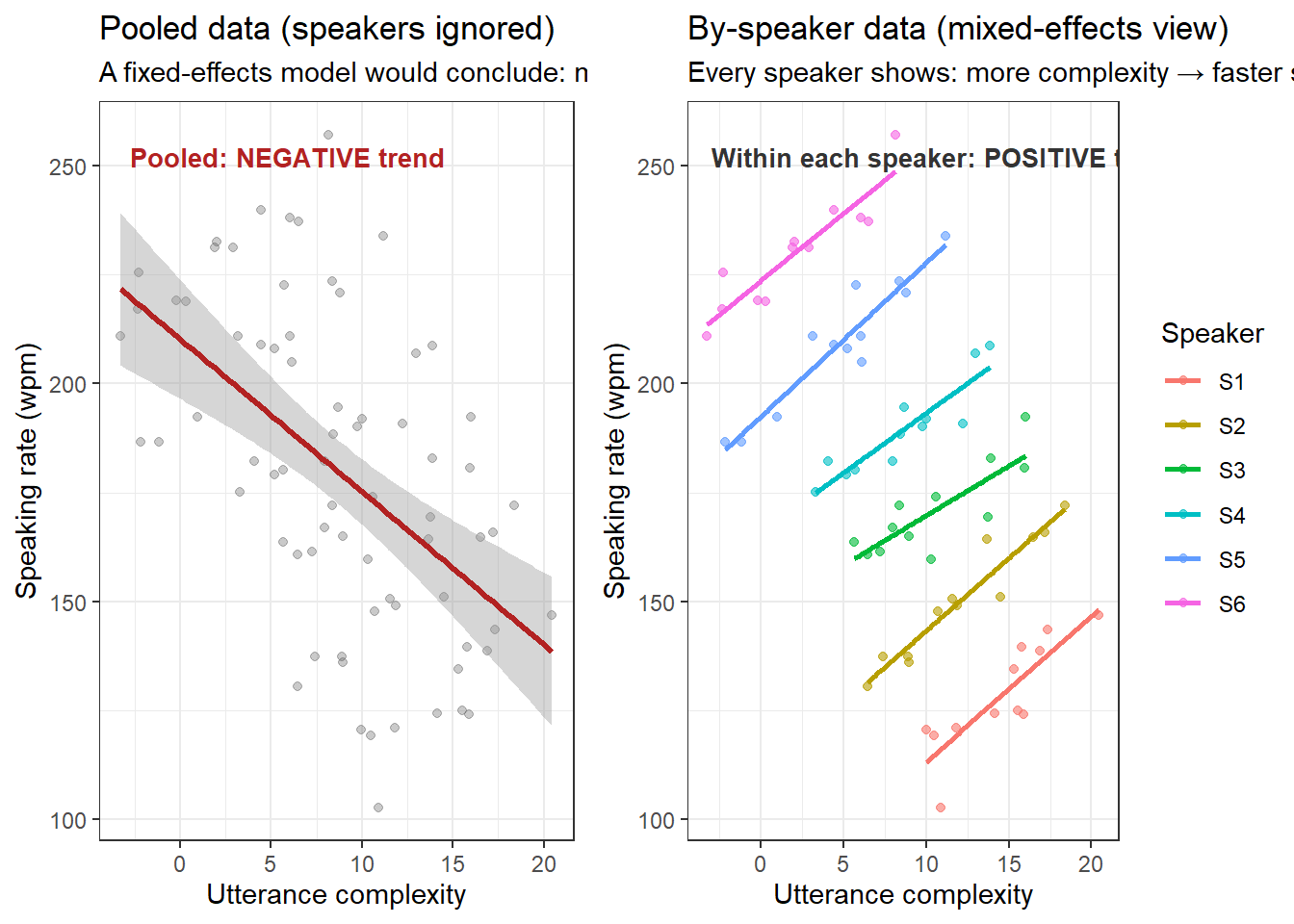
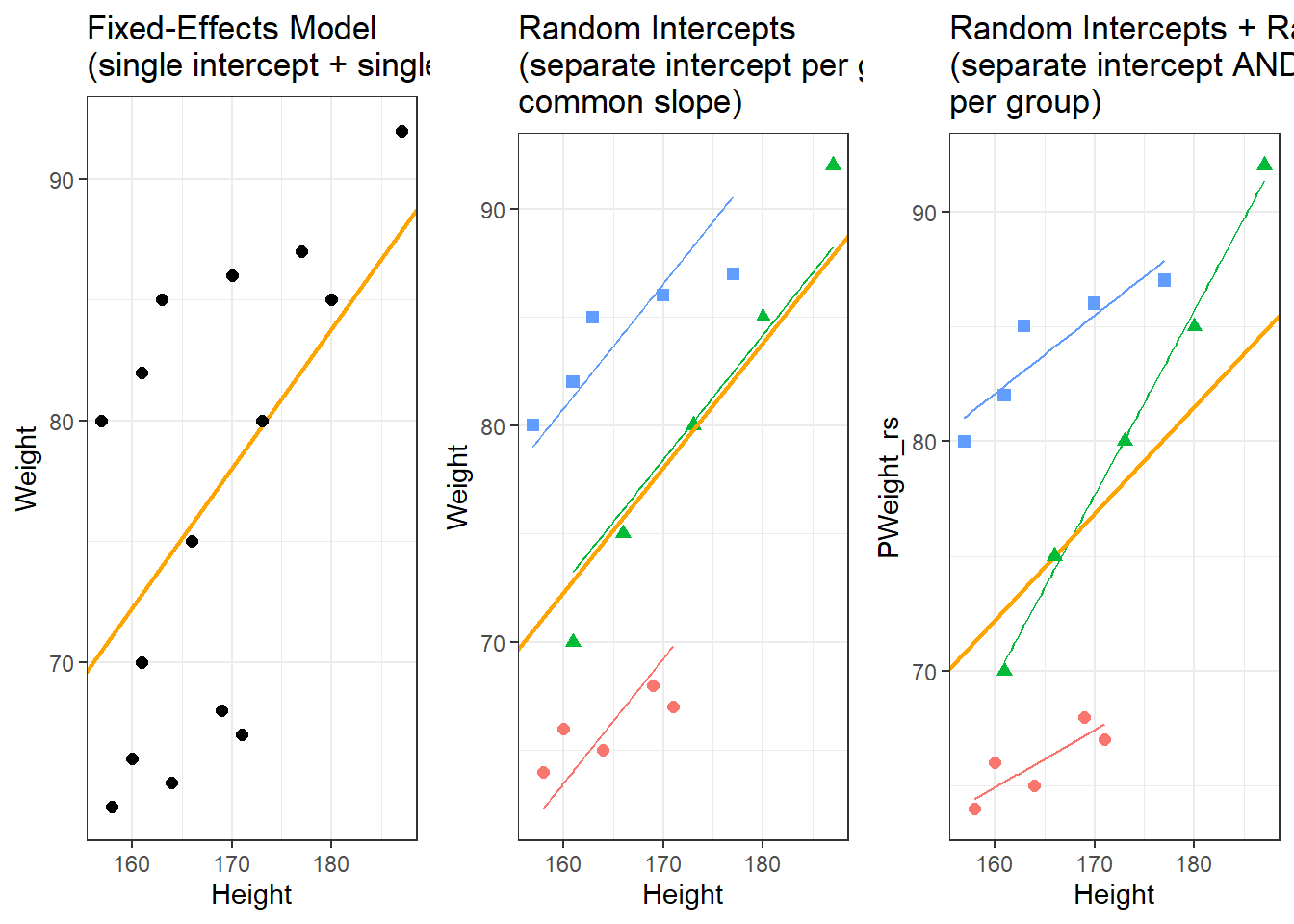
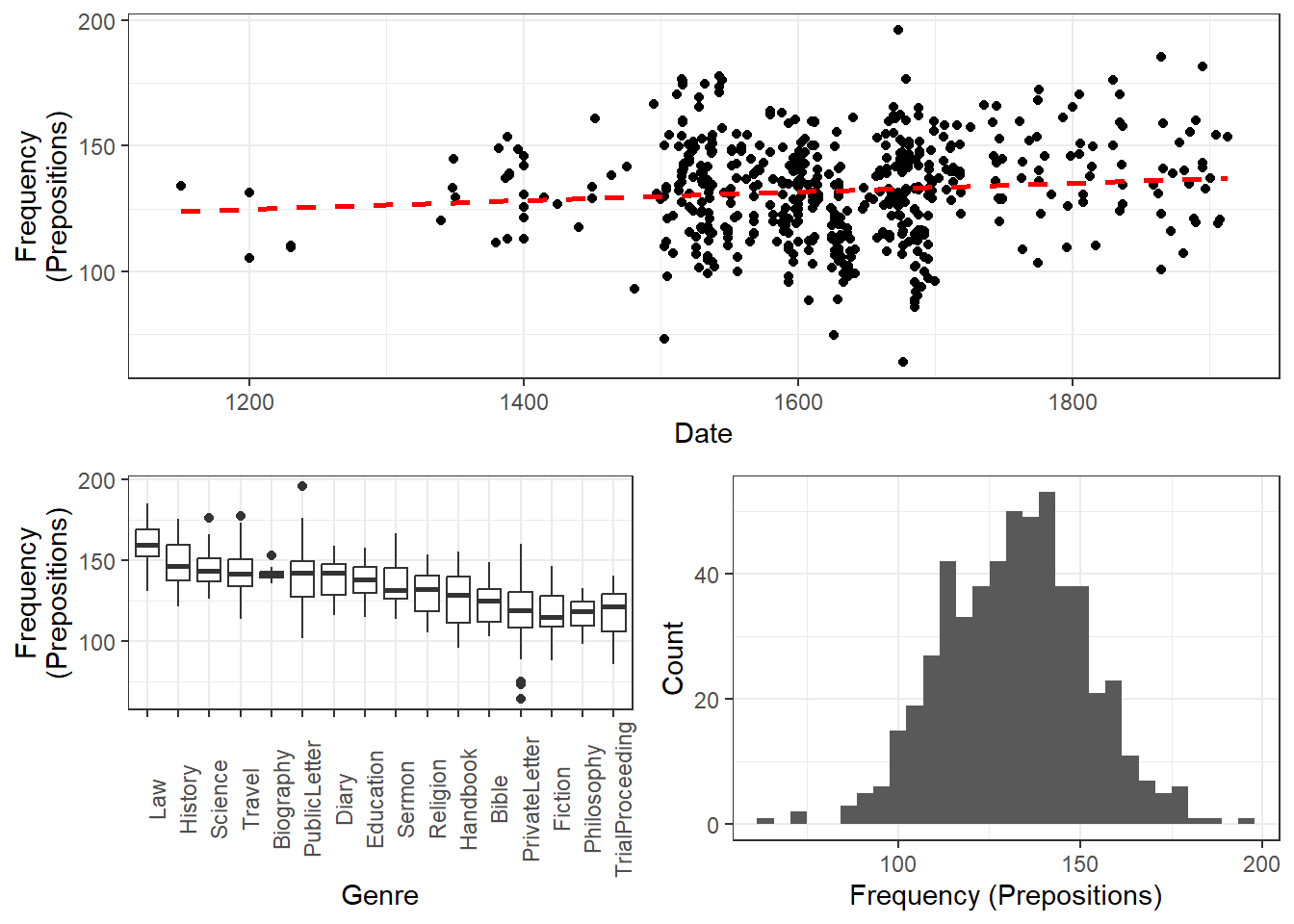
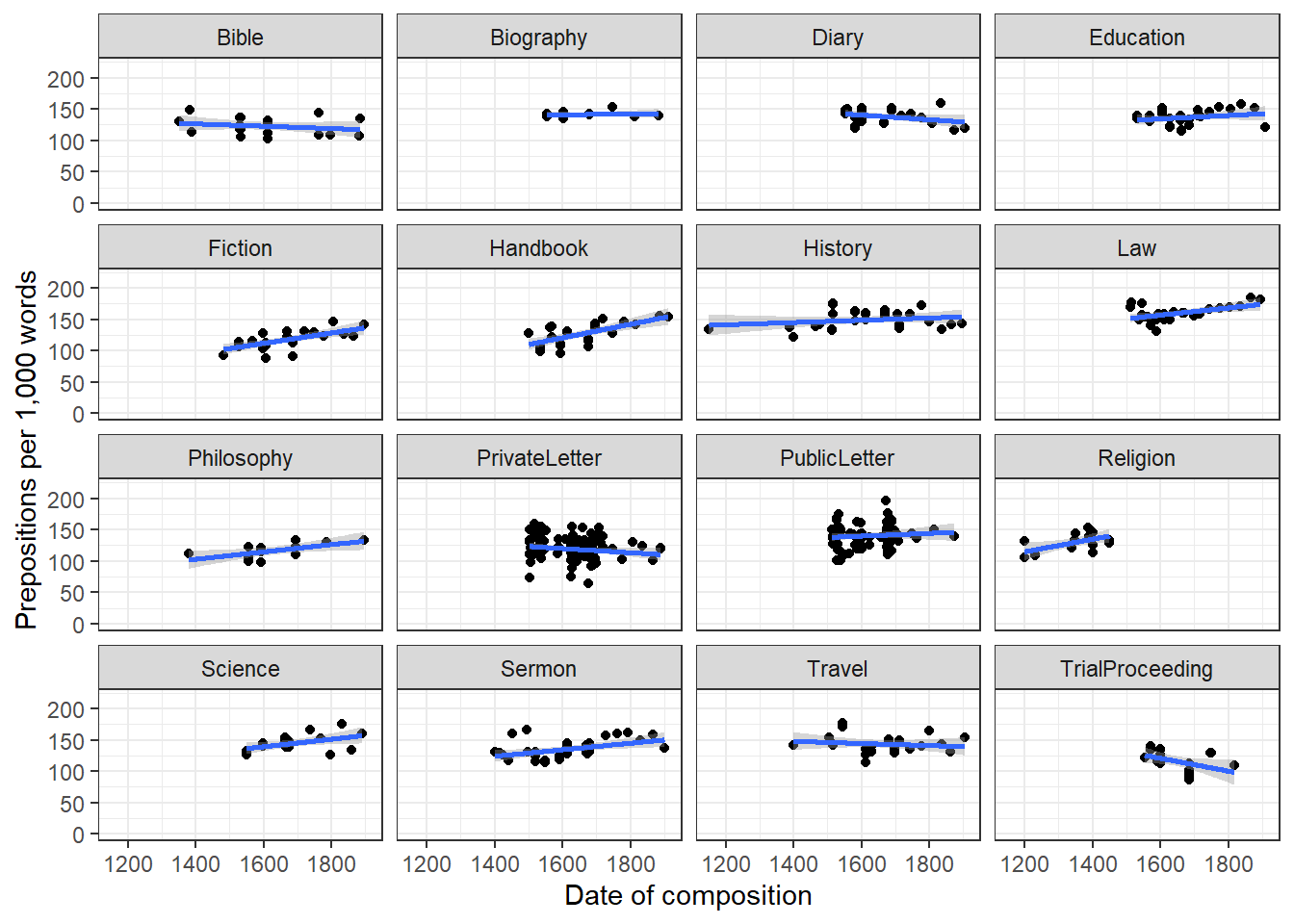
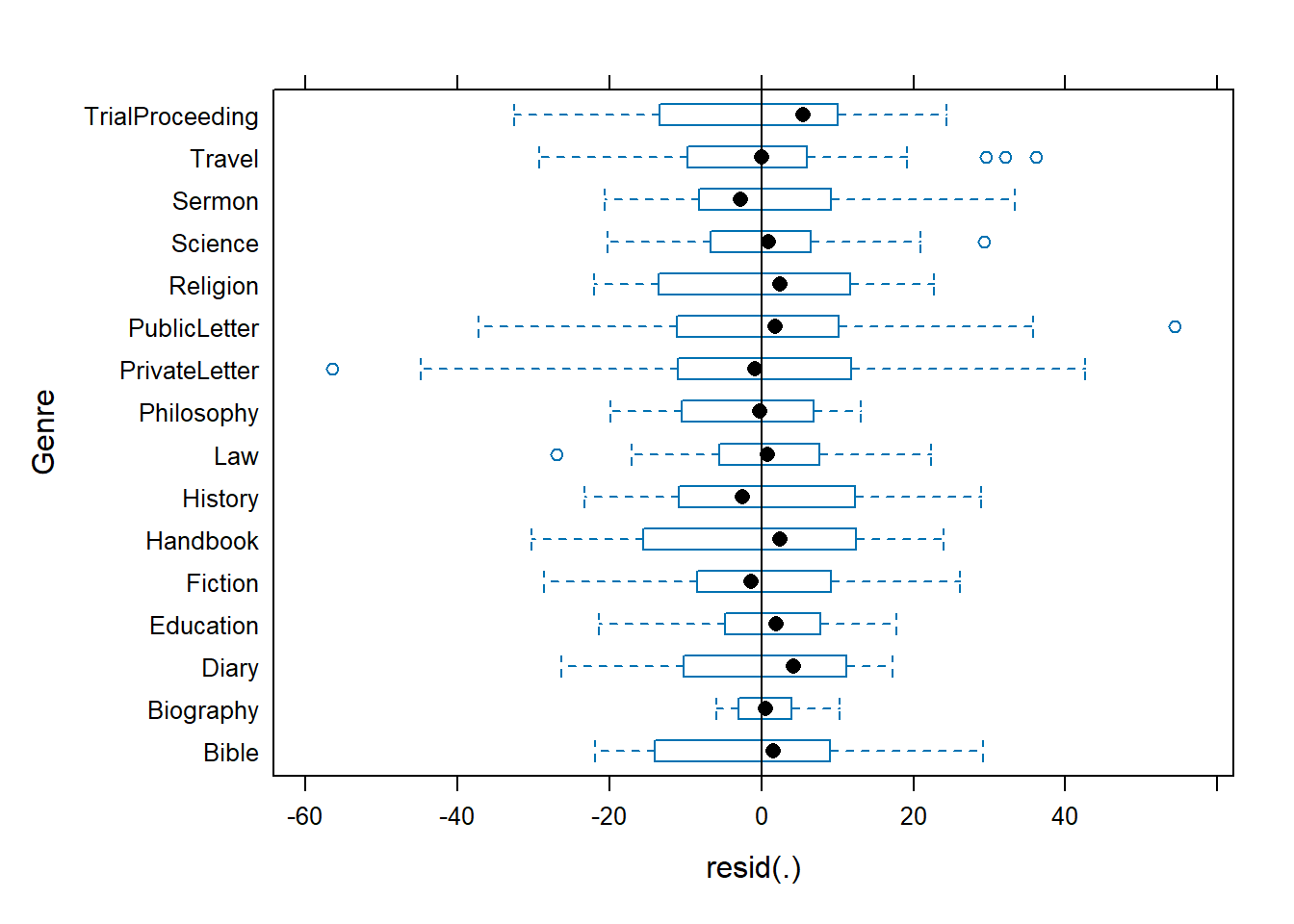
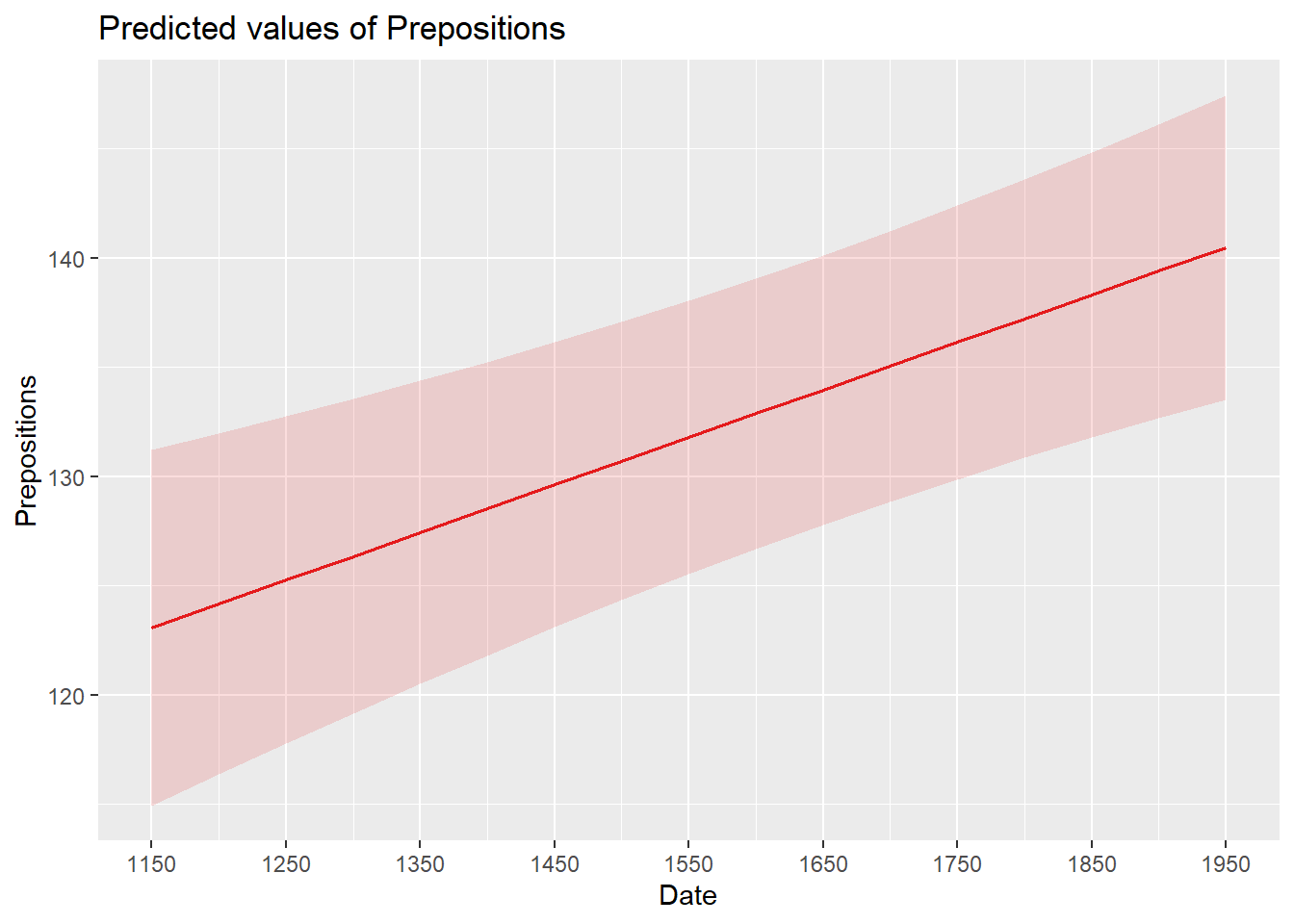
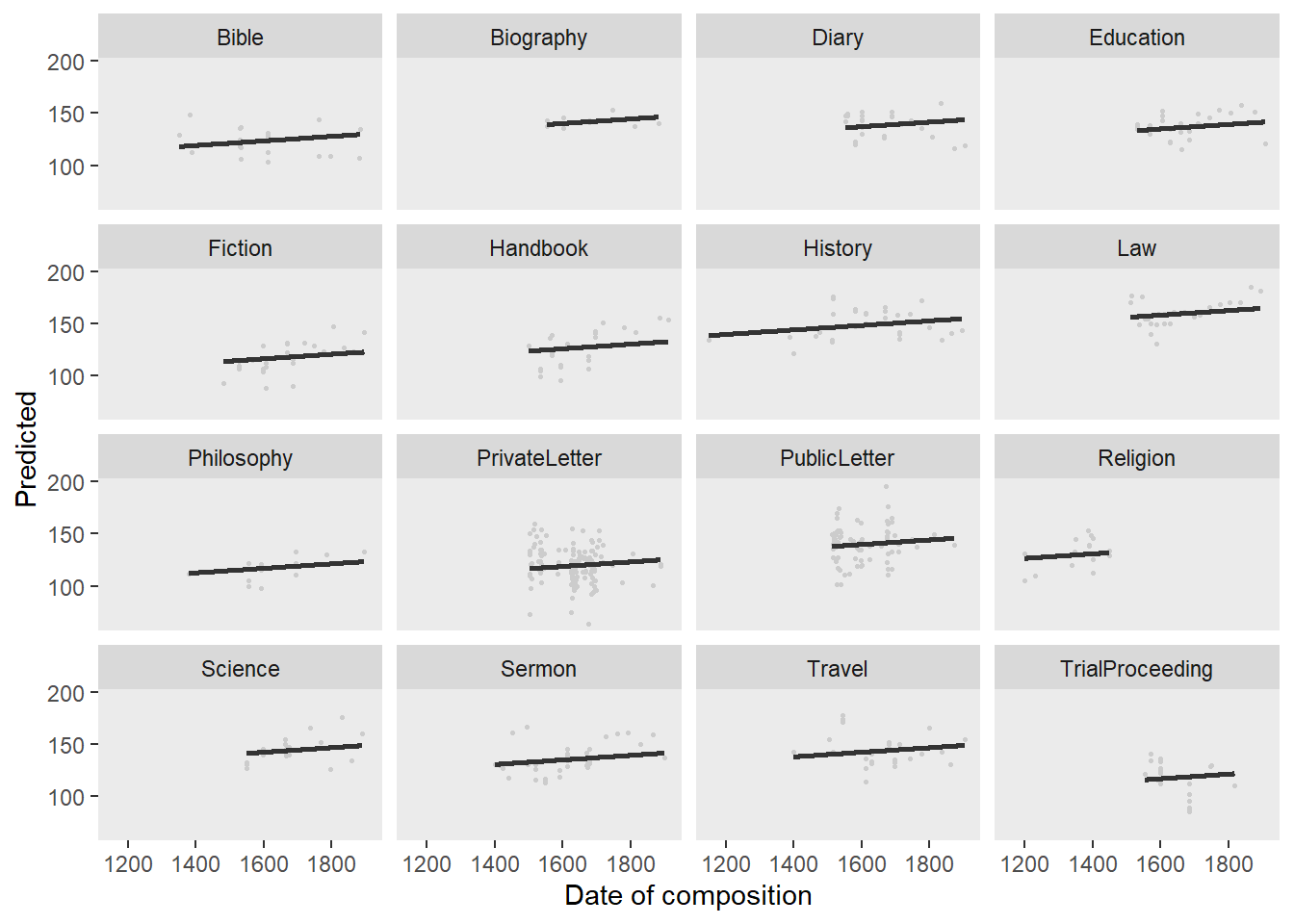
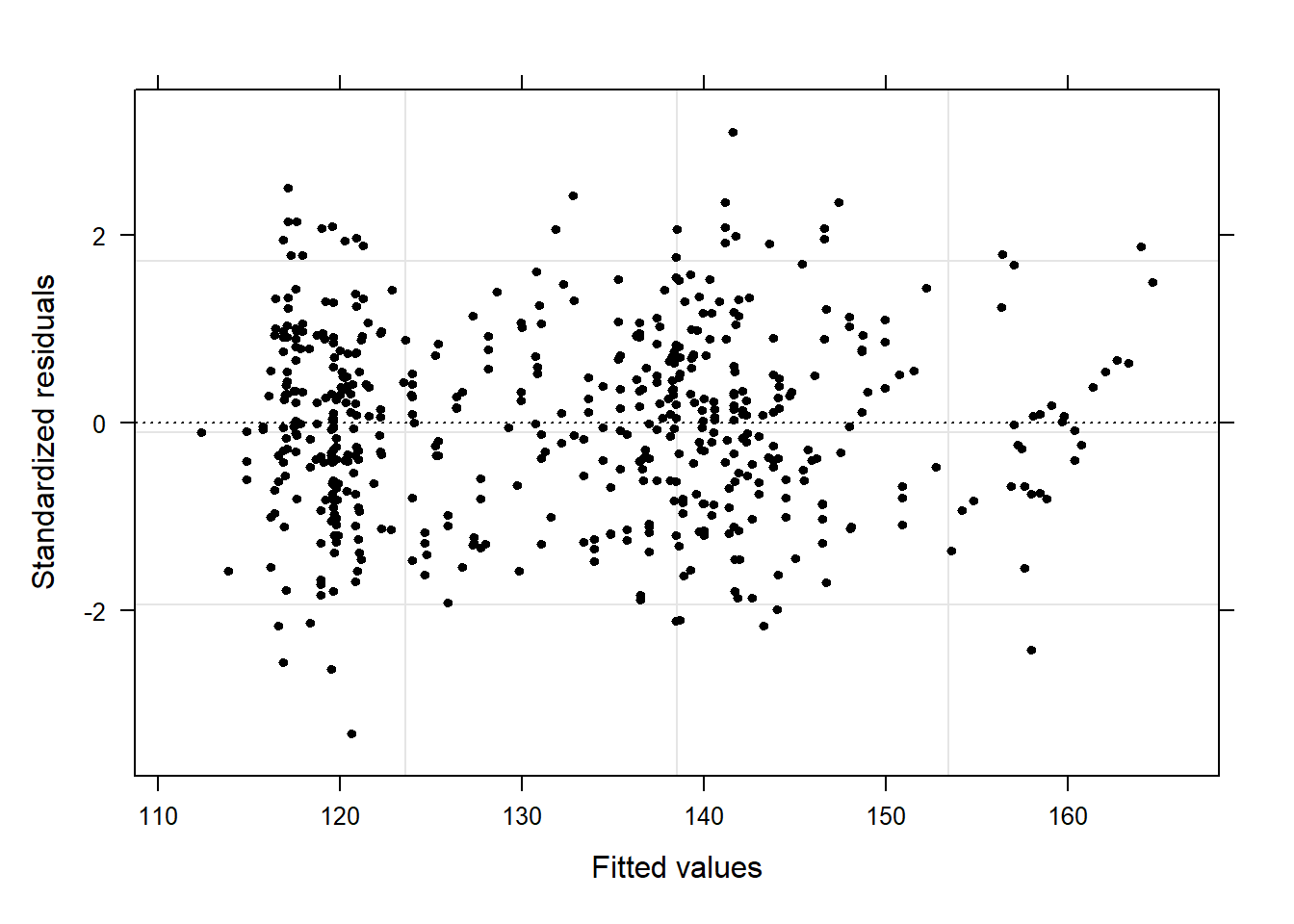
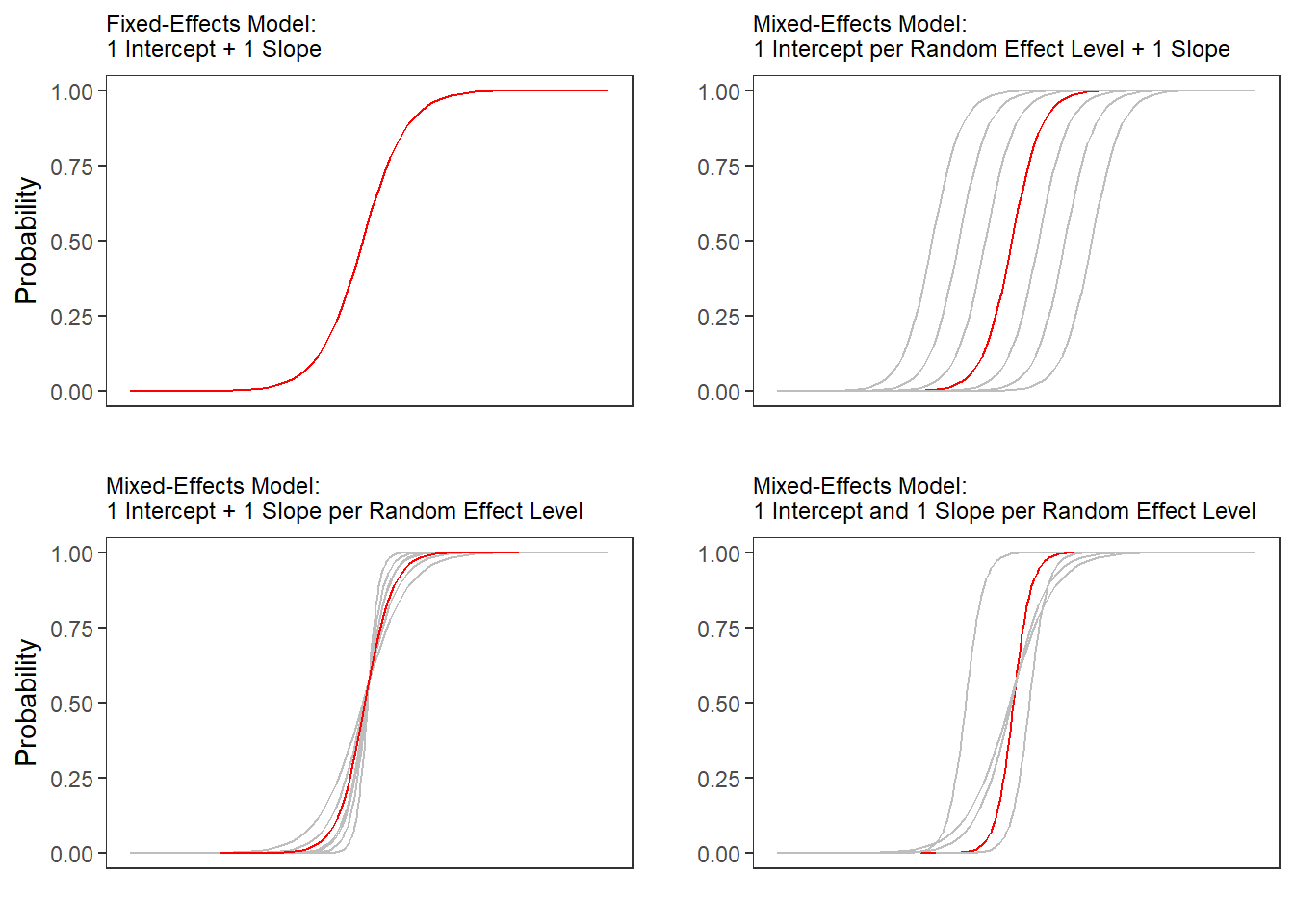
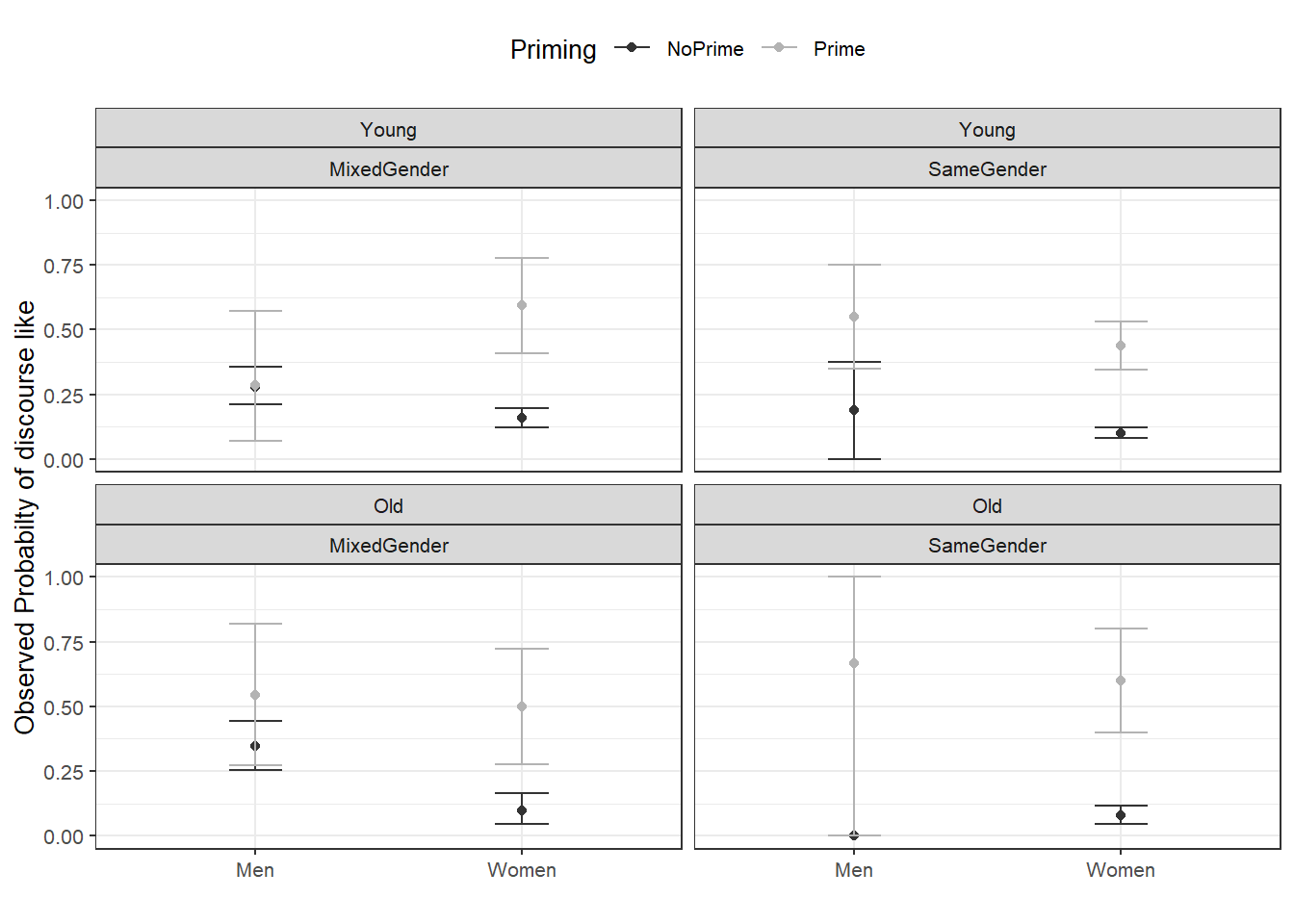
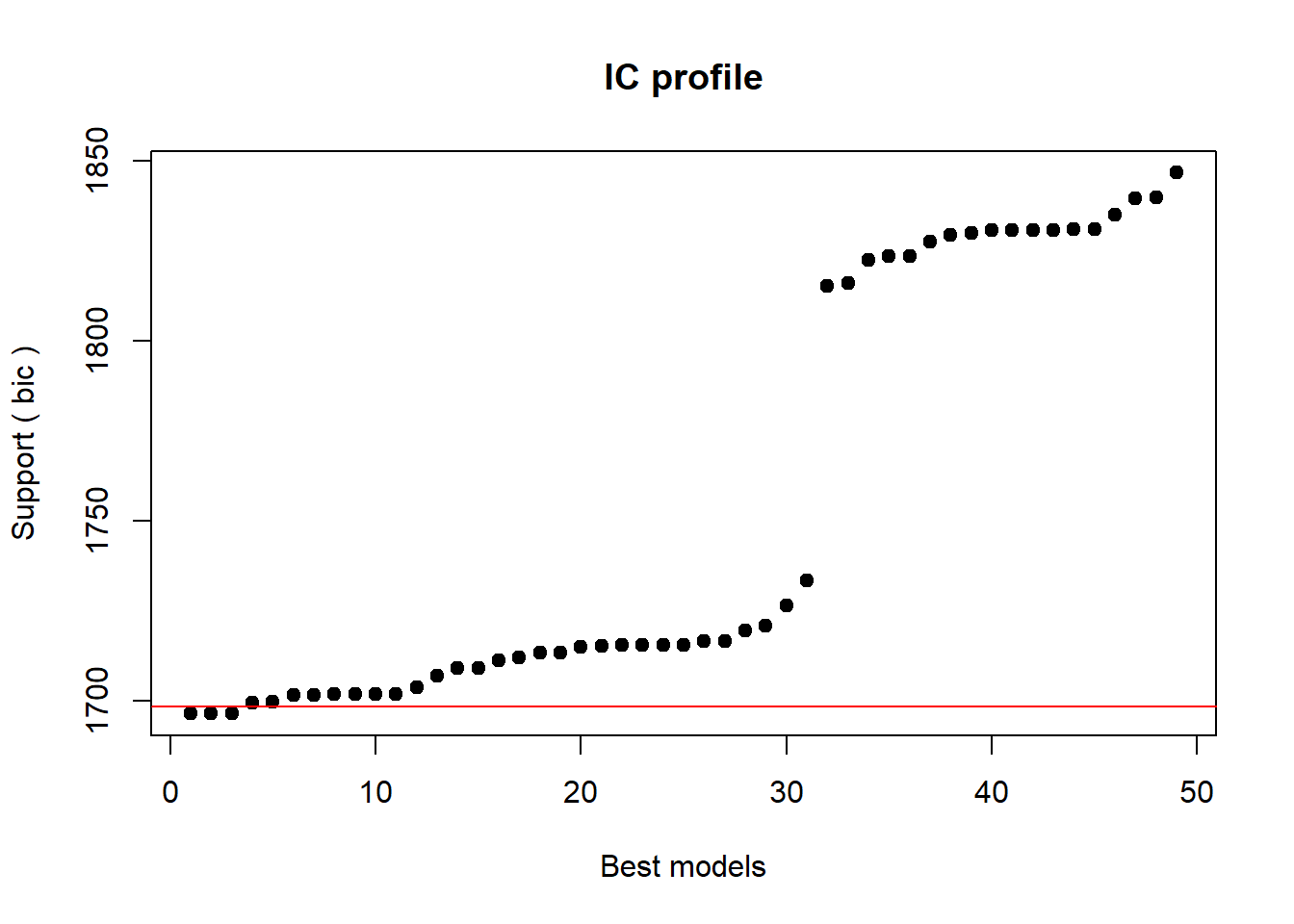
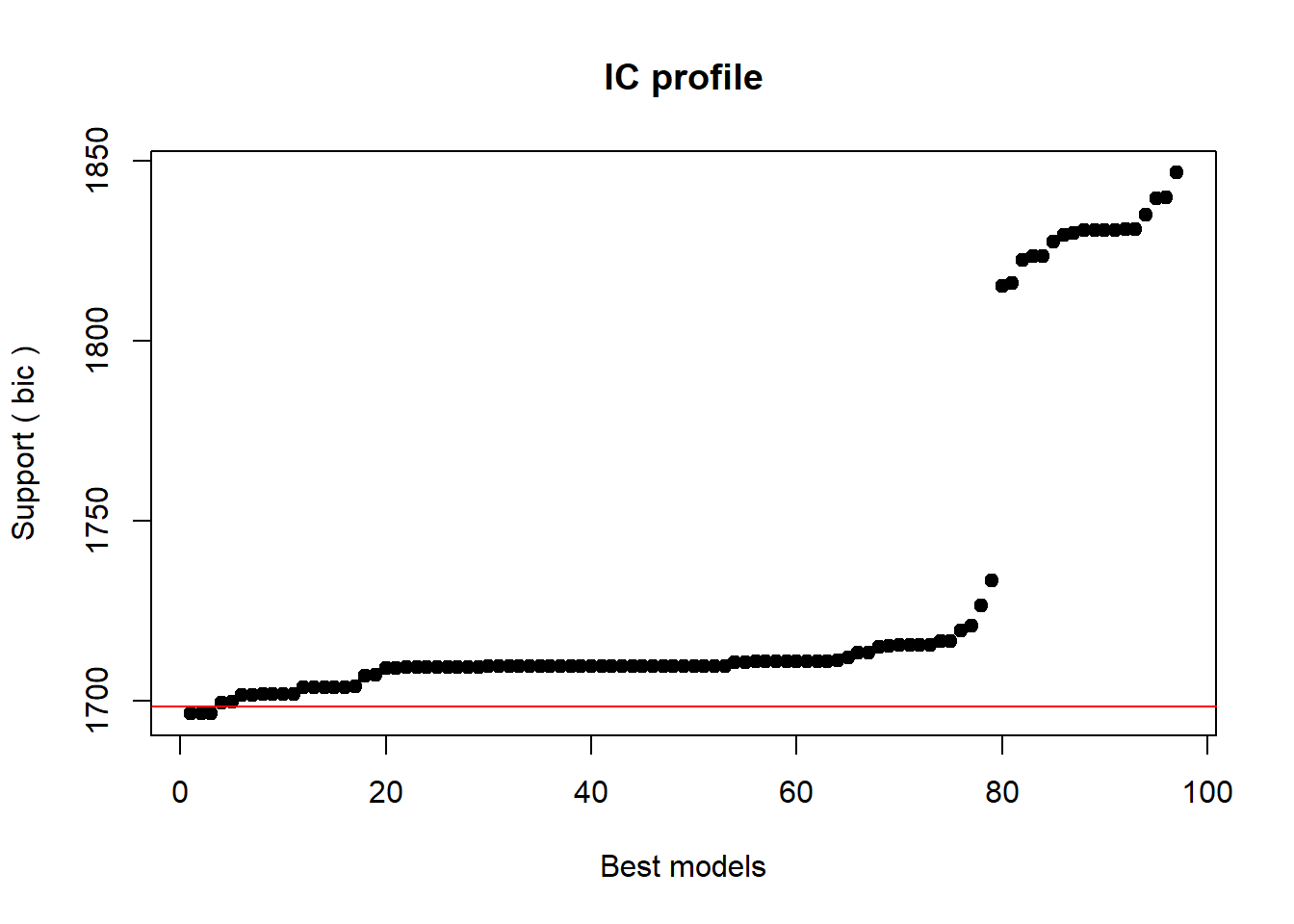
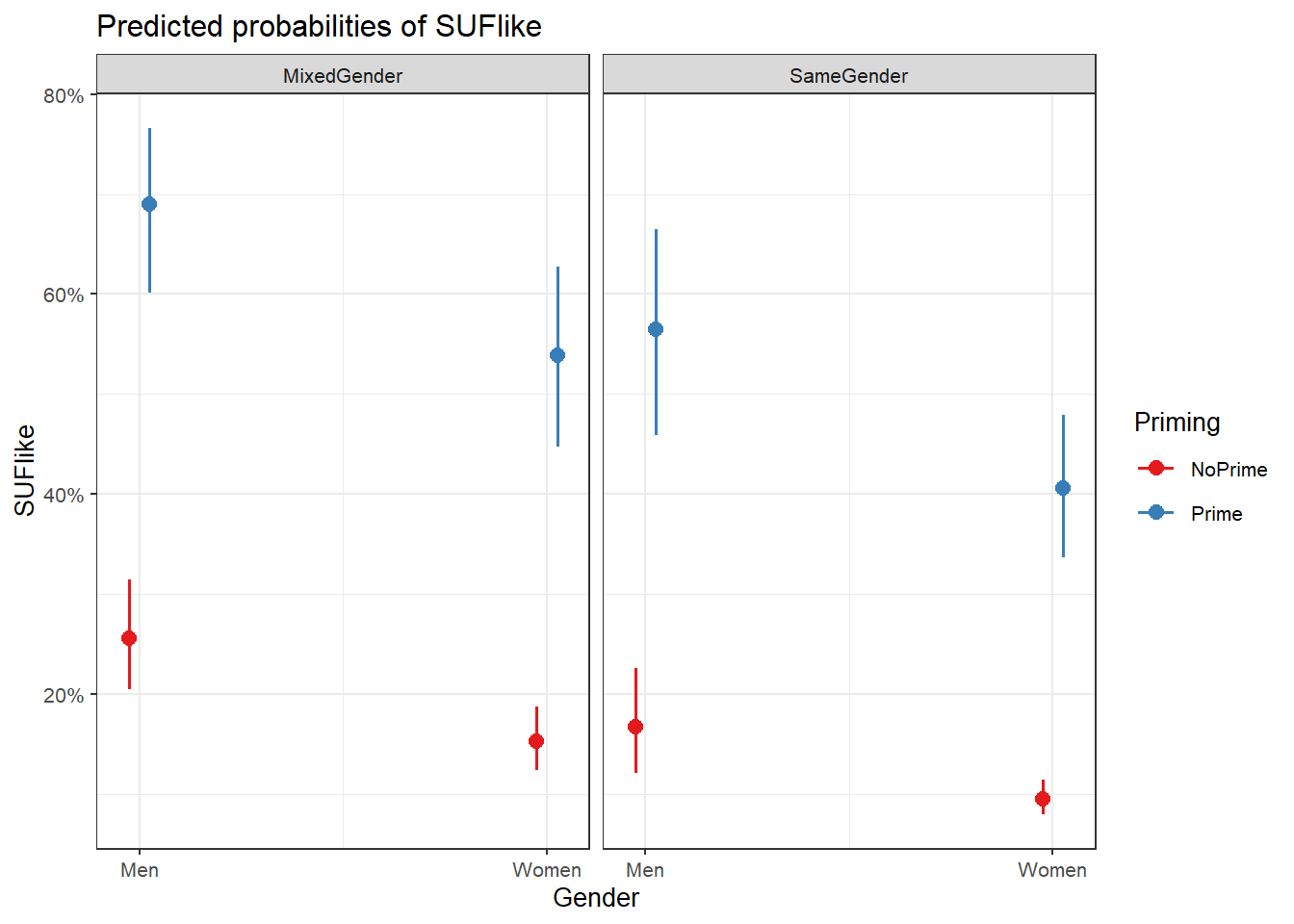
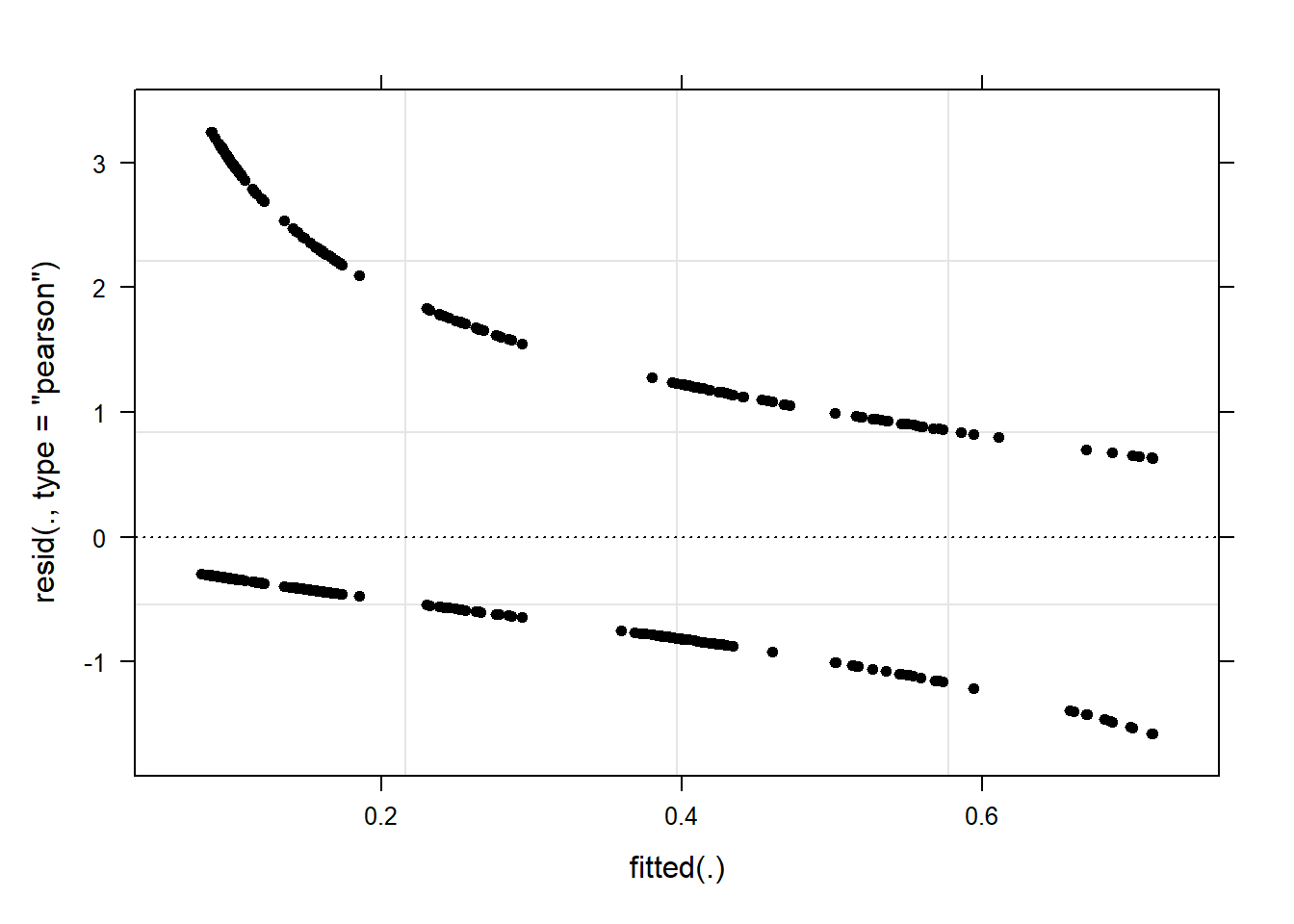
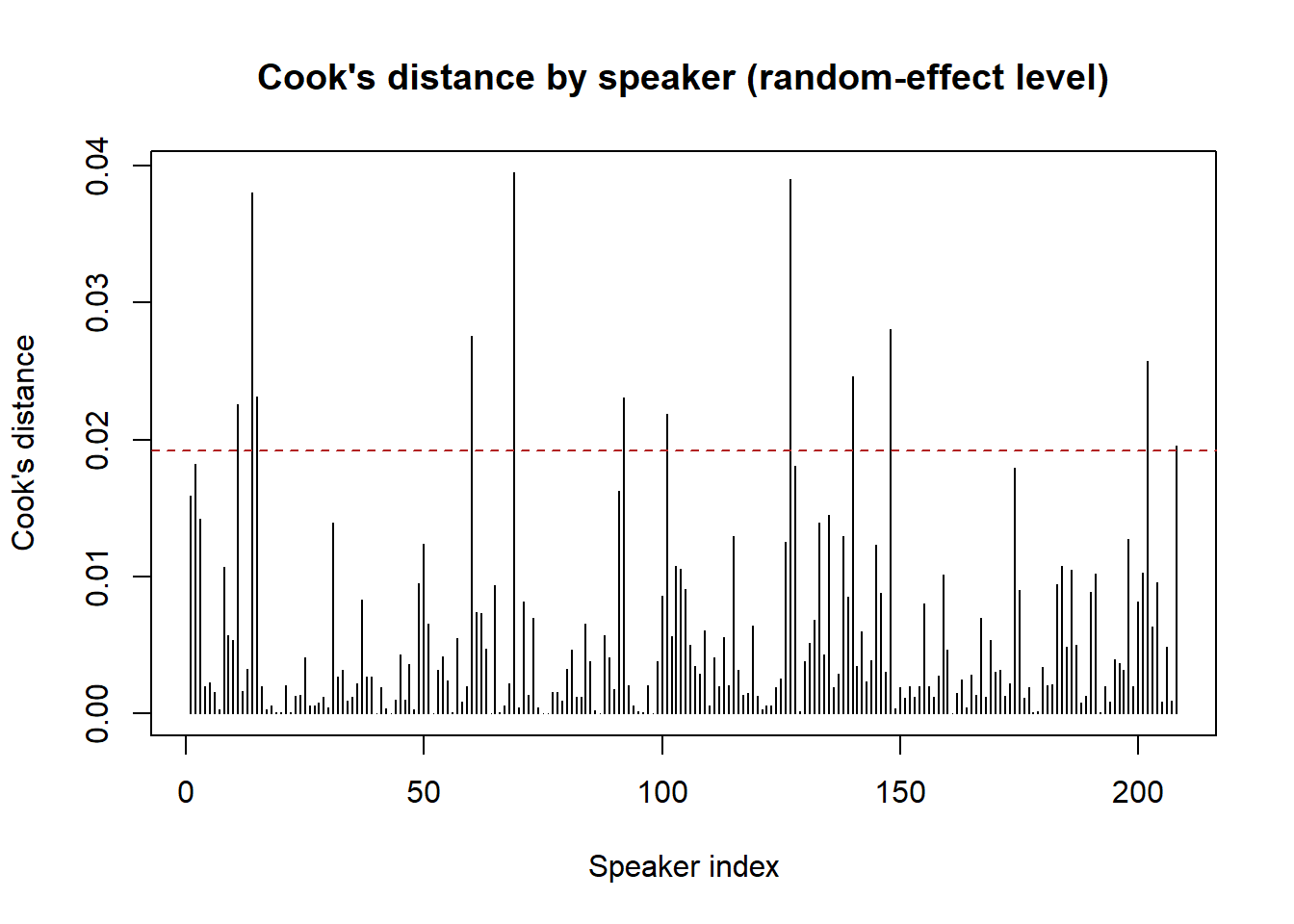
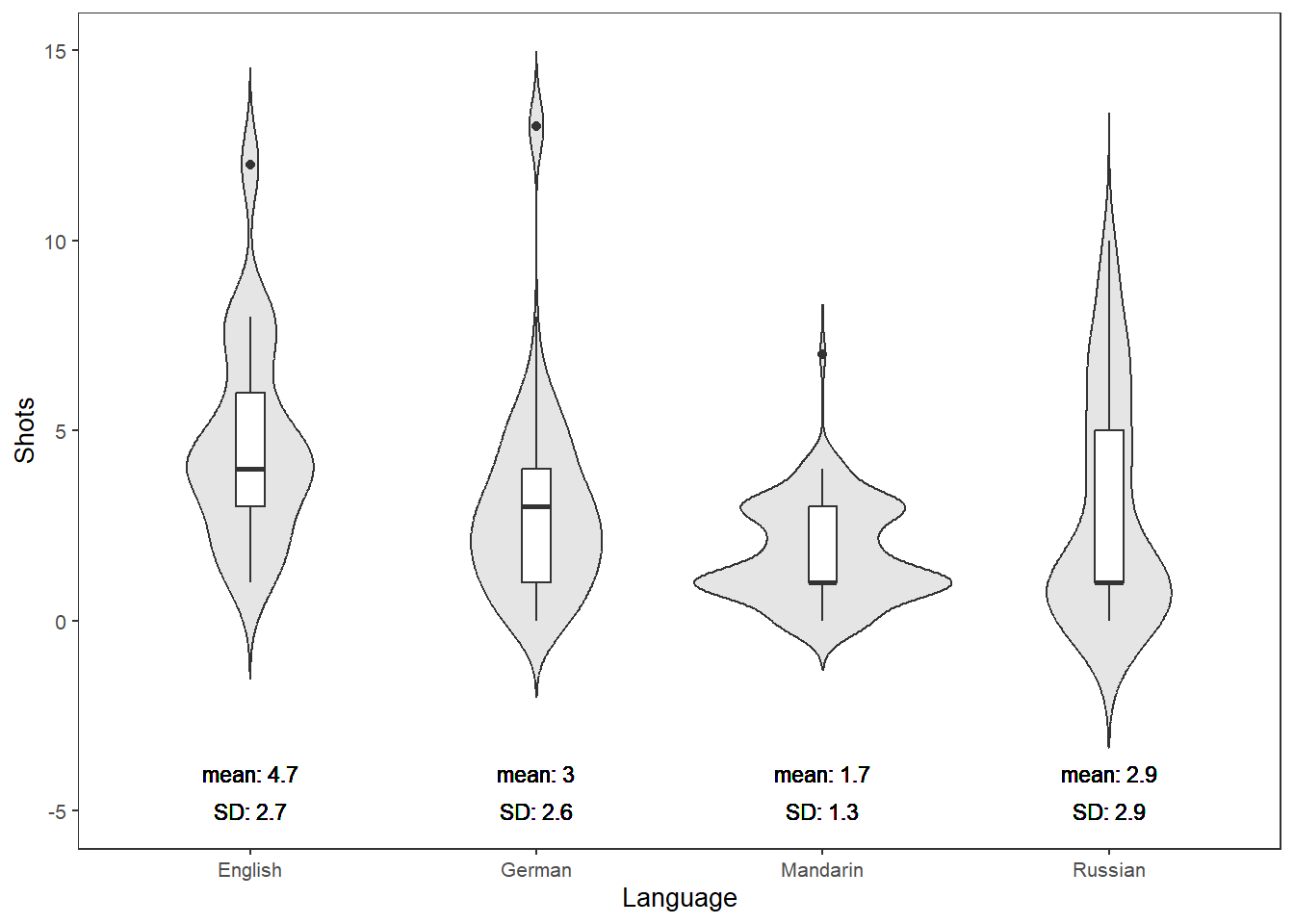
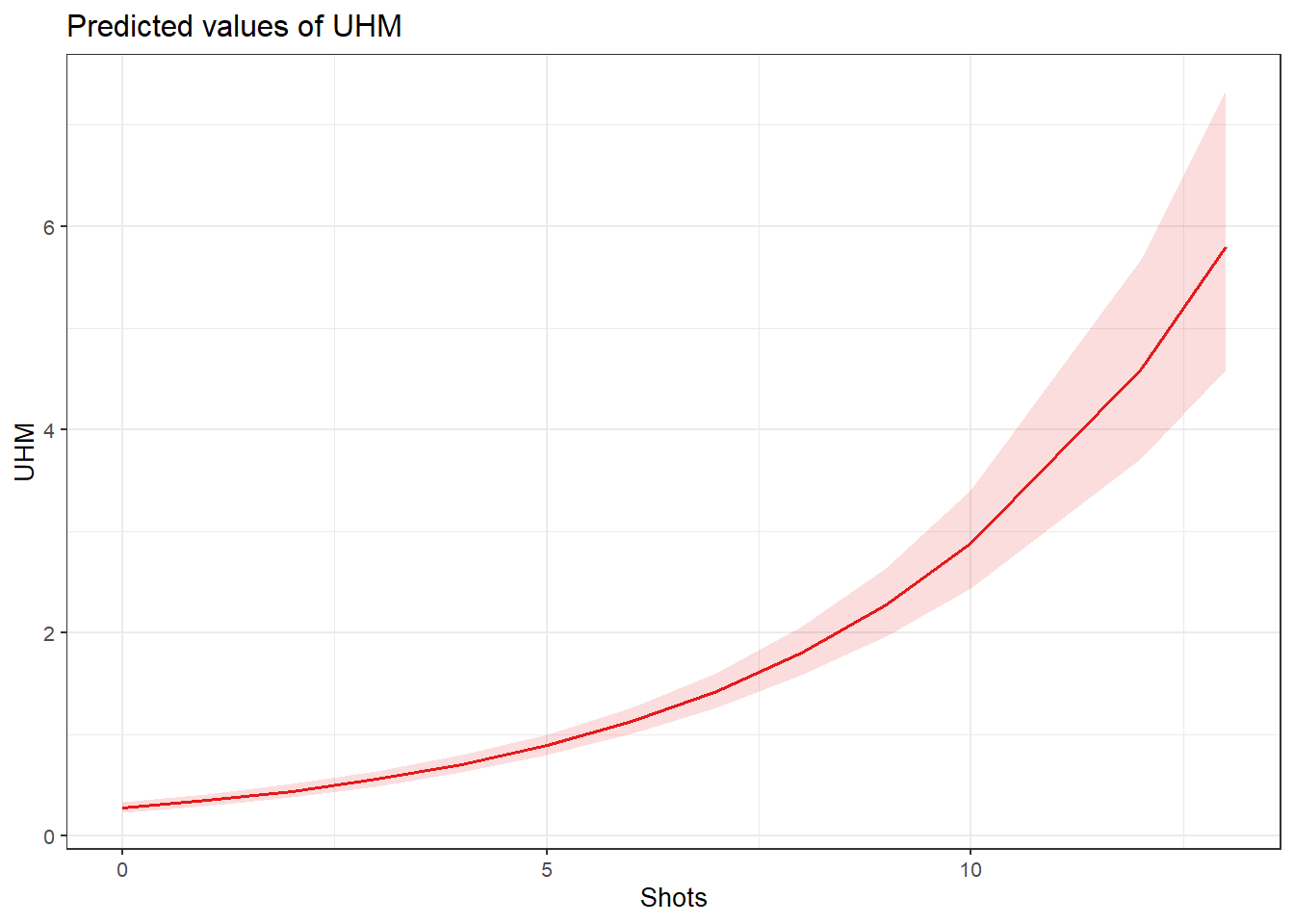
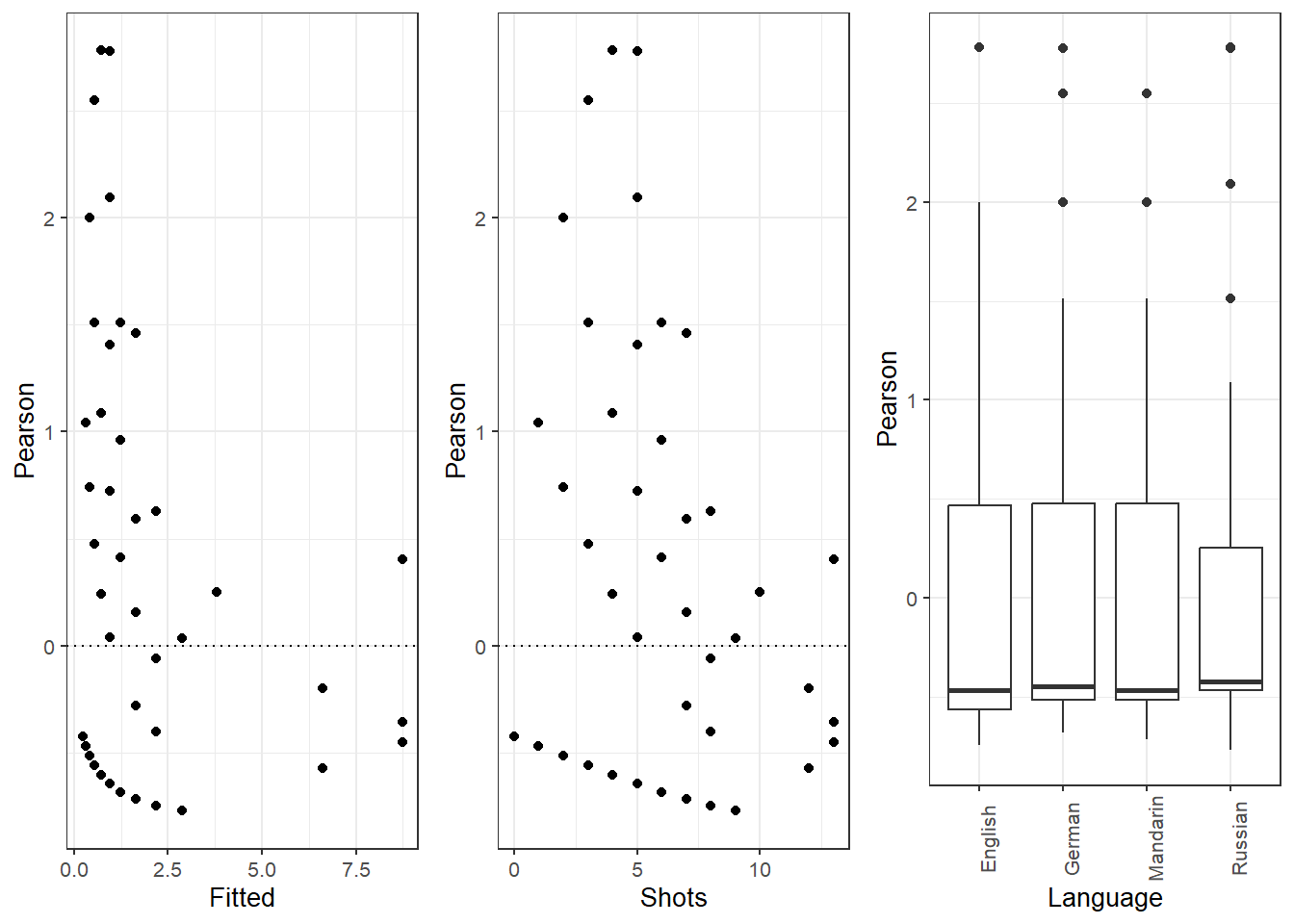
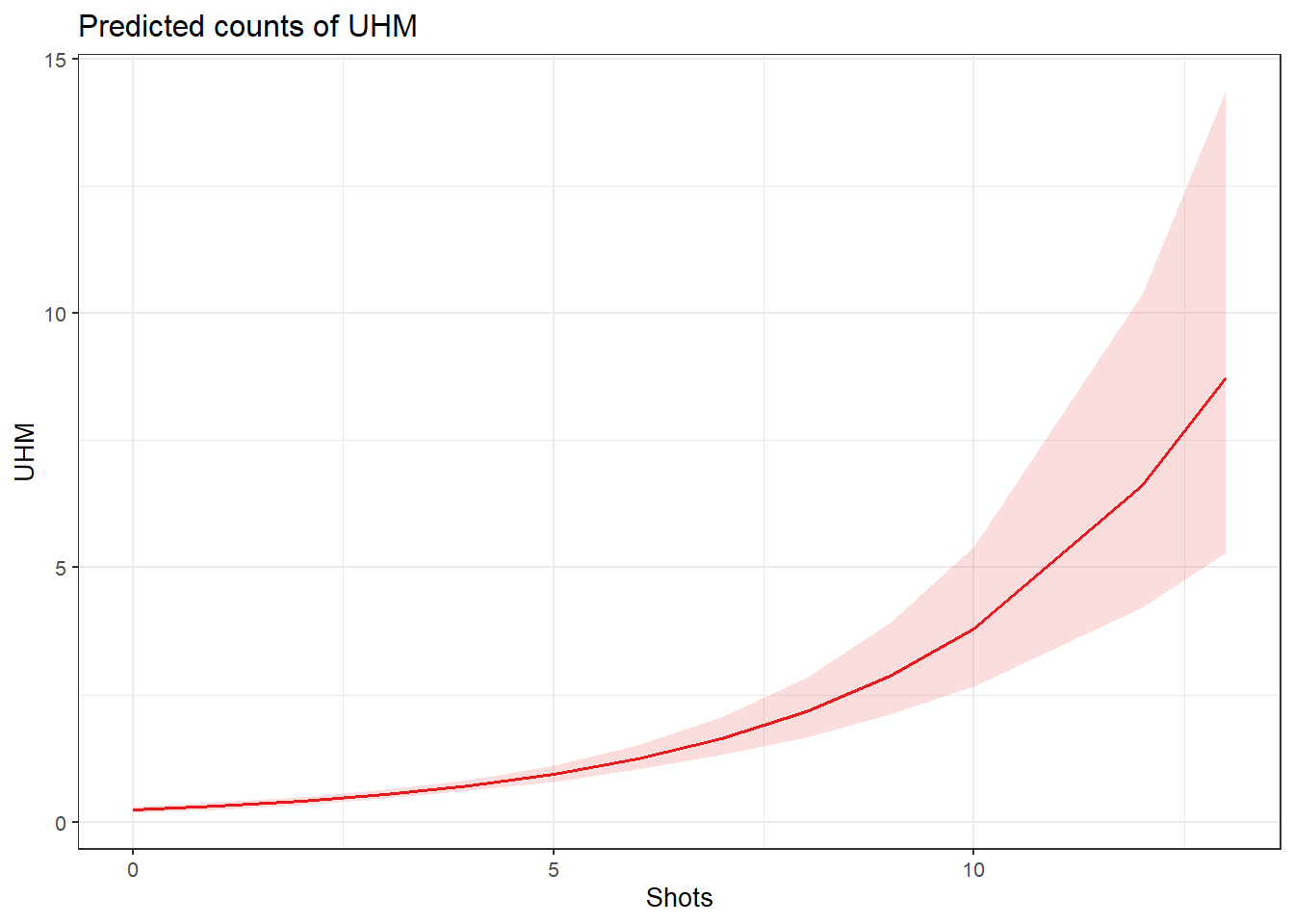
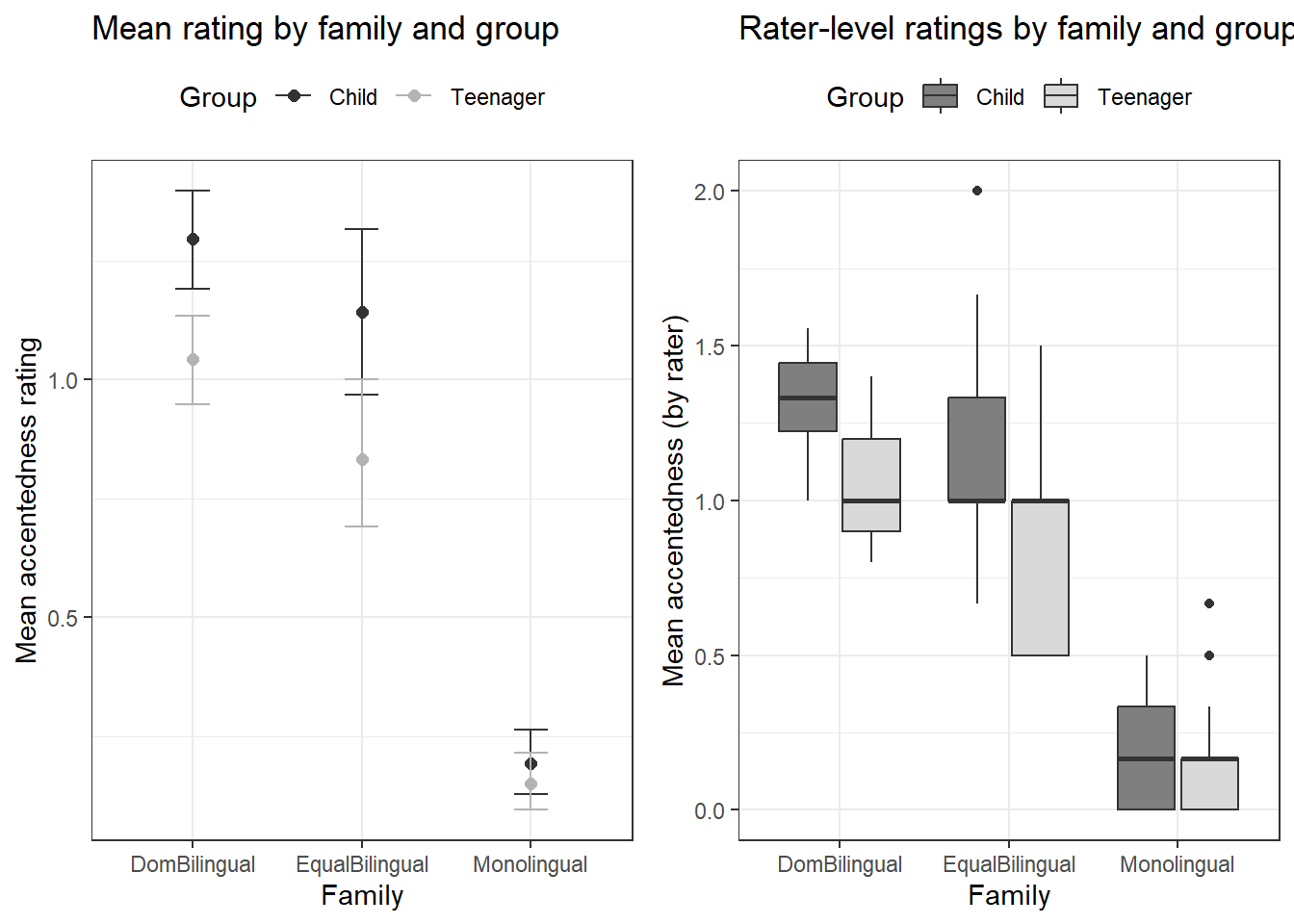
Barr, Dale J, Roger Levy, Christoph Scheepers, and Harry J Tily. 2013. “Random Effects Structure for Confirmatory Hypothesis Testing: Keep It Maximal.” Journal of Memory and Language 68 (3): 255–78.
Bartoń, Kamil. 2020.
“Package MuMIn - Multi-Model Inference.” The Comprehensive R Archive Network.
https://cran.r-project.org/web/packages/MuMIn/MuMIn.pdf.
Bell, Bethany A., John M. Ferron, and Jeffrey D. Kromrey. 2008. “Cluster Size in Multilevel Models: The Impact of Sparse Data Structures on Point and Interval Estimates in Two-Level Models.” In JSM Proceedings. Section on Survey Research Methods, 1122–29. American Statistical Association Alexandria, VA.
Christensen, R. H. B. 2019. “Ordinal—Regression Models for Ordinal Data.”
Johnson, Daniel Ezra. 2009.
“Getting Off the GoldVarb Standard: Introducing Rbrul for Mixed-Effects Variable Rule Analysis.” Language and Linguistics Compass 3 (1): 359–83. https://doi.org/
https://doi.org/10.1111/j.1749-818x.2008.00108.x.
Murayama, Kou, Michiko Sakaki, Veronica X Yan, and Garry M Smith. 2014. “Type i Error Inflation in the Traditional by-Participant Analysis to Metamemory Accuracy: A Generalized Mixed-Effects Model Perspective.” Journal of Experimental Psychology: Learning, Memory, and Cognition 40 (5): 1287.
Pinheiro, J. C., and D. M. Bates. 2000. Mixed-Effects Models in s and s-PLUS. Statistics and Computing. New York: Springer.
Winter, Bodo. 2019.
Statistics for Linguists: An Introduction Using r. Routledge. https://doi.org/
https://doi.org/10.4324/9781315165547.
Zuur, Alain F., Joseph M. Hilbe, and Elena N. Ieno. 2013. A Beginner’s Guide to GLM and GLMM with. R. Beginner’s Guide Series. Newburgh, United Kingdom: Highland Statistics Ltd.